
- En este artículo veremos el desarrollo de un modelo de trading basado en machine learning, utilizando indicadores técnicos y redes neuronales para predecir movimientos de precios y mejorar las estrategias de trading.
- Artículo publicado en Hispatrading Magazine 61.
“¿Alguna vez has pensado en una sesión de trading como… una flor?”
La primera vez que propuse este tema a mis gestores de fondos de cobertura, me miraron como si estuviera loco. Estoy seguro de que algunos comenzaron a murmurar y a preguntarse si habría comido algunas flores un poco raras. Sin embargo, estaba hablando en serio y permítanme explicar por qué
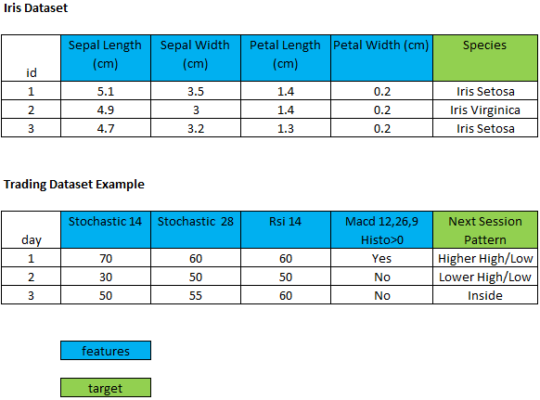
Retrocedamos a 1936 cuando un científico británico llamado Ronald Fisher desarrolló un “algoritmo” para reconocer especies de Iris basándose en algunas características numéricas. El conjunto de datos de Iris es el “Hola Mundo” de la Ciencia de Datos, comúnmente utilizado para practicar algoritmos básicos de Machine Learning (ML). Comprende cinco columnas: Longitud del Pétalo, Ancho del Pétalo, Longitud del Sépalo, Ancho del Sépalo y Tipo de Especie. Los investigadores midieron varias características de diferentes flores de iris y las registraron digitalmente. Fisher utilizó cuatro características: longitud del sépalo, ancho del sépalo, longitud del pétalo y ancho del pétalo para clasificar tres especies de iris (Setosa, Versicolor, Virginica).
Así, mi idea era: ¿qué pasaría si seguimos una linea de investigación similar y clasificamos las sesiones de trading en cuatro especies (o patrones) como se muestra en el ejemplo en la Fig. 1? En lugar de pétalos y sépalos, podríamos usar lecturas de indicadores técnicos de sesiones anteriores.
Cuando los traders experimentados miran los gráficos, a diferencia de los novatos, no intentan predecir el futuro. En cambio, tratan de reconocer patrones que han observado en su experiencia. En más detalle, buscan patrones incompletos para realizar una operación antes de su finalización. Hagamos una comparación entre los dos mundos: flores y trading. En la Fig. 2, puedes comparar el conjunto de datos de Iris con el conjunto de datos de trading que estoy proponiendo. Si estructuramos el conjunto de datos de trading de esta manera, el problema de clasificación es exactamente el mismo. No importa si tienes que reconocer una flor o una sesión de trading. Además, no importa si la última columna del conjunto de datos de trading está relacionada con el futuro, ya que este enfoque no se basa en el tiempo y el conjunto de datos de trading NO se analiza como una serie temporal.

Cómo Funciona el Modelo de IA
Entremos en los detalles utilizando algunos conceptos básicos de Python. Los traders que no estén familiarizados con este lenguaje deben saber que la mayoría de las herramientas necesarias para aplicar modelos de machine learning están integradas. No necesitas ser científico para trabajar con ellas. Lo que sí necesitas es un propósito claro y, como trader, tu propósito es obtener información sobre el movimiento del precio de la próxima barra.
Conozco a muchos traders experimentados que no están familiarizados con Python y no tienen tiempo para aprenderlo. Sin embargo, créanme, es más fácil para un trader captar algunos conceptos básicos de Python que para un científico de datos sin experiencia en el mercado aprender a operar. ¿Por qué? Espero no ofender a ningún científico de datos (muchos de los cuales son amigos) cuando digo que si estudias programación, eventualmente puedes aprender cualquier lenguaje de programación. En contraste, si estudias trading, no hay manera de aprender sin práctica real en el mercado. Esto requiere tiempo, dinero y una increíble cantidad de energía psicológica y motivación para perseverar a través de los numerosos fracasos que enfrentan los traders.
Ahora enfoquémonos en el mercado. En mi experiencia como desarrollador cuantitativo para fondos de cobertura, colaboré estrechamente con cientos de traders profesionales experimentados para construir sus herramientas de trading personalizadas. Muchas veces escuché frases como “Cuando el precio hace este movimiento, es muy probable que la próxima barra haga esto o aquello.” ¿Qué están haciendo? Están aplicando algún tipo de modelo personal que han desarrollado a lo largo de años de observación y trading. Esto es precisamente cómo funciona el modelo de machine learning que estoy presentando.
Así que el modelo intenta responder preguntas como:
¿Puede la lectura del oscilador Estocástico de hoy ayudar a predecir si mañana se dará un patrón Higher High/Low?
¿Puede la lectura del oscilador RSI de hoy ayudar a predecir si mañana tendrá un patrón Higher High/Low?
¿Puede el histograma del MACD de hoy, por encima de 0, ayudar a predecir si mañana hará un patrón Higher High/Low?
En términos generales, los traders usan las lecturas actuales de los indicadores/osciladores para obtener información sobre el movimiento de la próxima barra. Sin embargo, la relación exacta entre los indicadores técnicos y el movimiento de la próxima barra es difícil de calcular porque no hay una función lineal clara entre ellos. A veces, el indicador está arriba y el precio sigue subiendo, mientras que otras veces ocurre lo contrario.
Aquí es donde entra en juego Python. Todo lo que necesitamos está disponible en sus bibliotecas para que los traders las utilicen. Veamos cómo proceder.
- Cargar Datos (el paso más fácil): En este ejemplo, cargué 20 años de barras diarias de USDJPY desde un archivo CSV exportado desde Tradestation.
- Establecer Características y Objetivo (el paso más crucial para los traders técnicos): Para el propósito de este artículo, consideré tres indicadores técnicos estándar.
- Estocástico (14)
- RSI (14)
- MACD (12, 26, 9)
El objetivo del modelo es predecir si la sesión de mañana tendrá un día de Higher High/Low (Objetivo del Modelo).
- Entrenamiento y Prueba del Modelo: Python utilizó sus bibliotecas de ML para analizar los primeros 12 años de datos de USDJPY (desde 2000 hasta 2012) para encontrar el mejor ajuste entre las características y el objetivo del modelo. Luego, Python aplicó el mejor modelo obtenido a los siguientes 10 años de datos fuera de muestra (desde 2013 hasta 2023).
- Puntuación: Python me informa si todos estos esfuerzos tienen sentido calculando una puntuación de precisión que va de 0 a 1 y generando una matriz.
- Predicción: Python me proporciona una predicción para mañana respondiendo a la pregunta: ¿Es probable que mañana se forme un patrón Higher High/Low? Sí o No.
- Trading: para realizar una operación basada en la predicción.

Indicadores Técnicos como Características para el Modelo de ML
Hablemos brevemente sobre la selección de características. En los modelos de machine learning, es muy importante que los datos estén normalizados, es decir, que estén dentro de un rango definido o que sean binarios (0/1). Utilicé tres indicadores técnicos muy comunes para construir el modelo. Dejé las lecturas del Estocástico y el RSI tal como están (ya que varían de 0 a 100 y ya están normalizadas) y simplifiqué la lectura del MACD con una característica binaria: histograma del MACD > 0 se asigna un valor de 1, mientras que histograma del MACD < 0 se asigna un valor de 0.
Muchos científicos de datos prefieren transformar los datos. La transformación de datos es el proceso de tomar datos crudos del mundo real y convertirlos en algo que pueda ser utilizado por una computadora. Es un paso importante en cualquier proyecto de ML, pero puede ser confuso y complicado; por eso elegimos lecturas técnicas listas para poder usarse.
Validación del Modelo
Una matriz de confusión es una herramienta comúnmente utilizada en machine learning y estadísticas para evaluar el rendimiento de un modelo de clasificación, como un clasificador binario. Proporciona un resumen de las predicciones del modelo en comparación con los valores reales en un formato tabular. El propósito principal de una matriz de confusión es ayudar a evaluar la precisión del modelo y su capacidad para clasificar correctamente las diferentes clases.
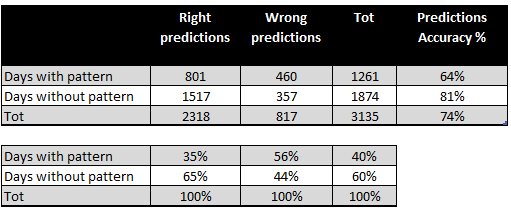
En la Fig. 4, puedes ver una matriz de confusión basada en 3000 días de datos en muestra y 3000 días de datos fuera de muestra para USDJPY. Hay un total de 3135 días fuera de muestra (desde enero de 2011 hasta septiembre de 2023). De estos, 1261 días mostraron el patrón Higher High/Low y el modelo predijo correctamente 801 de ellos (64%). Por otro lado, 1874 días no mostraron el patrón y el modelo predijo correctamente 1517 de ellos (81%). La precisión total del modelo es del 74%.
Plan de Trading
- Suponiendo que confiamos en el modelo, aquí está el plan de trading:
- Comprar al cierre cuando la predicción es alcista con un stop loss en el mínimo actual.
- Vender en corto al cierre cuando la predicción es bajista con un stop loss en el máximo actual.
- Salir al cierre de la próxima barra.
Backtest y Walk-Forward Analysis (WFA)
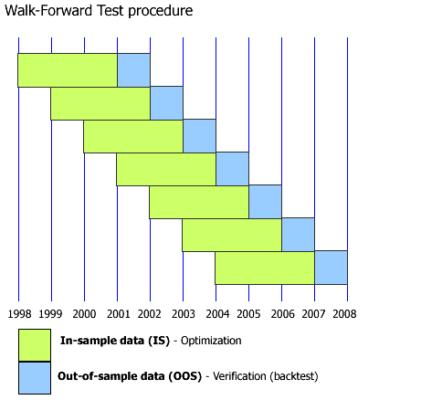
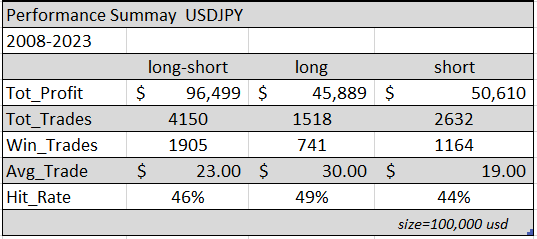
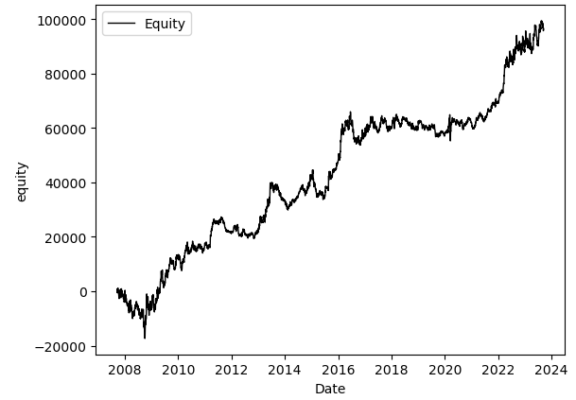
Realizamos backtesting en USDJPY para el período 2008-2023 aplicando la metodología de walk-forward. El análisis walk-forward implica dividir el proceso de entrenamiento y prueba en varias partes (ver Fig. 5). En este ejemplo, el modelo pasó por un walk-forward de 2000/50, lo que significa que se entrenó en 2000 días y luego se probó en los siguientes 50 días fuera de muestra. Recomendamos encarecidamente realizar dicho análisis para cualquier sistema de trading, no solo aquellos basados en ML. Muchas plataformas de trading ofrecen esta útil función y es esencial someter tus sistemas a este proceso. En la Fig. 6 encuentras un resumen del rendimiento y en la Fig. 7 la correspondiente línea de equidad.
Conclusión
Entonces, ¿podemos pensar en un día de trading como una flor? Yo diría que sí, porque los patrones de trading pueden ser representados por una combinación binaria al igual que una especie de Iris. La principal diferencia es que necesitamos reconocer algo que aún no ha sucedido.
¿Es bueno este modelo de machine learning? Podemos decir que sí, porque la precisión es alta y la matriz de confusión tiene sentido.
¿Podemos usar este modelo para operar con dinero real? Bueno, el backtest arrojó resultados positivos. Las operaciones largas y cortas están bastante equilibradas y la curva de rentabilidad muestra un crecimiento constante. Sin embargo, necesitamos trabajar en mejorar el promedio de la operación, ya que es bastante bajo al considerar los spreads y comisiones del broker. No obstante, estamos satisfechos con nuestro primer modelo de inteligencia artificial aplicado al trading y confiamos en que estamos en el camino correcto.