
- Mediante Machine Learning podemos encontrar estructuras y patrones tan complejos y enterrados entre el ruido de los mercados que ningún ojo humano los podría detectar. Veremos cómo obtener ventaja aplicando técnicas de Machine Learning en nuestra operativa.
- Artículo publicado en Hispatrading 16.
Con el auge de los gigantes de la tecnología de la información (Google, Facebook, Apple, etc) la ciencia de la Inteligencia Artificial ha empezado a renacer. Con nombres tan futurísticos como Machine Learning, Metaheuristics o Data Mining se engloba toda una serie de algoritmos y tecnologías orientadas a procesar la hiperabundante información y transformarla en conocimiento explotable.
La cuestión central que estudia el Machine Learning es la siguiente: ¿cómo podemos diseñar sistemas computacionales que automáticamente mejoren con la experiencia y cuáles son las leyes fundamentales que gobiernan este proceso de aprendizaje?
Con Machine Learning podemos construir sistemas que aprendan de los datos. Un ejemplo típico es el sistema que reconoce el spam de nuestro buzón de correo, para ello se entrena al sistema con miles de emails de spam a modo de ejemplo para que posteriormente clasifique nuestro correo entrante según lo que ha aprendido.
En general se trata de conseguir que una computadora aprenda a reconocer patrones y características de una serie de datos o bien que encuentre y nos muestre una posible estructura oculta en los datos imperceptible a nuestros ojos. En definitiva enseñamos al ordenador a clasificar y predecir información para nosotros.
Por otra parte, los mercados financieros son la mayor fuente de datos de alta frecuencia y por tanto perfectos candidatos para experimentar con estas tecnologías. ¿Podemos aplicar Machine Learning para mejorar nuestro trading? Para responder a esta pregunta veamos antes la diferencia entre los sistemas automáticos clásicos basados en reglas lógicas y los nuevos sistemas basados en modelos de Machine Learning.
Sistemas de trading basados en reglas y basados en modelos
Los sistemas de trading automático clásicos se basan en conjuntos de reglas predefinidas por un trader. Estas reglas dan forma a la estrategia que el trader ha desarrollado a lo largo del tiempo con su experiencia negociando en los mercados. Hablamos de las reglas de compra y venta a la señal de una combinación de indicadores o de la rotura de un precio de soporte o resistencia, de filtros de volatilidad y tendencia mediante indicadores como el ATR y el Momentum, etc.
Los sistemas basados en modelos son diferentes. En vez de buscar reglas para operar lo que hacen es utilizar un modelo que analiza información buscando un patrón que con alta probabilidad continúa en determinado movimiento del mercado. Por ejemplo podemos introducir en nuestro modelo los valores del RSI de las últimas 3 sesiones y programar al sistema para que aprenda la relación (si la hubiera) entre estos datos y la volatilidad de la próxima sesión.
La tabla 1 es un ejemplo de valores para entrenar el modelo. Los tres primeros valores (RSI D1, RSI D2, RSI D3) son las entradas y el último (VOLATILIDAD) representa el objetivo a predecir. Cada fila de la tabla contiene los valores de la sesión. Entrenaremos a nuestro sistema introduciéndole los datos con esta información (por ejemplo de 300 sesiones) y finalmente le daremos los valores de entrada de la sesión actual (tabla 2) para que prediga el valor del objetivo (VOLATILIDAD).
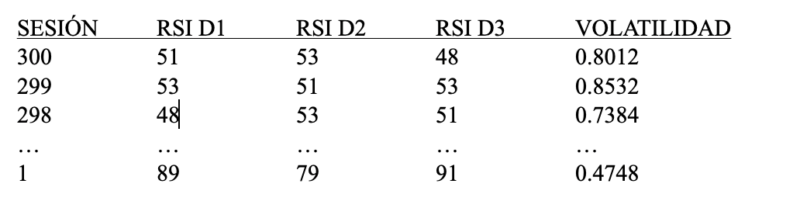

Esta información podría sernos muy valiosa de forma que componiendo modelos que clasifican y predicen el mercado construyamos un sistema de trading automático.
Diferencias entre los sistemas basados en reglas y basados en modelos
Se puede obtener sistemas automáticos basados en reglas que sean realmente predictivos si se hace bien, es decir, sometiendo al sistema a un riguroso análisis estadístico. De hecho, la clave del trading automático reside en saber medir correctamente mediante el análisis estadístico la probabilidad de que el rendimiento pasado de nuestro sistema no sea debido a la suerte sino a que está detectando y explotando a su favor una ineficiencia real del mercado.
Pero los sistemas automáticos clásicos siempre dependerán de la experiencia y conocimiento del mercado que posea el trader para encontrar ineficiencias que explotar. Aquí es donde las técnicas de Machine Learning pueden ayudarnos muchísimo y puede ser la mayor diferencia entre ambas técnicas de desarrollo de sistemas.
Mediante Machine Learning podemos hacer que el ordenador busque estructuras y patrones tan complejos y enterrados entre el ruido de los mercados que ningún ojo humano los podría detectar. Además de ésto los elementos que componen este tipo de sistemas nos permiten aplicar técnicas de análisis estadístico avanzado de manera más sencilla que con los sistemas basados en reglas.
Una última ventaja, no poco importante, de los sistemas basados en modelos es que al no ceñirse a una señal fija de compra o venta sino a una probabilidad de acierto en la predicción nos permiten ajustar el espectro de riesgo y beneficio del sistema y construir carteras más agresivas o conservadoras en función de nuestro perfil inversor.
Vamos a ver con dos ejemplos cómo podemos aprovechar estas dos características de los modelos de Machine Learning. Para la clasificación de estructuras en la información podemos utilizar el algoritmo o modelo k-means clustering y tanto para la predicción como para el ajuste de riesgo veamos un sistema de trading basado en una red neuronal simple.
El algoritmo k-means clustering para seleccionar parámetros en conjuntos multidimensionales
Uno de los pasos fundamentales en el diseño de sistemas de trading es la reoptimización periódica de sus parámetros. Cuando optimizamos un sistema estamos probando miles de combinaciones posibles en el histórico de datos para saber qué combinación daba los mejores resultados.
Uno podría cometer el error de elegir directamente el conjunto de parámetros que más beneficio hubiese dado, lo que nos garantizaría seguramente un problema. Con toda probabilidad este conjunto será fruto de una sobreoptimización y operar con él en forwardtest nos llevará a la ruina.
Es mucho mejor buscar un conjunto de parámetros positivo que tenga otros conjuntos cercanos de similares características, es decir buscar «vecinos parecidos» para asegurarnos que estamos en un «buen barrio».
Cuando optimizamos dos parámetros es relativamente fácil hacerlo de manera visual, por ejemplo en la figura 1 se ve claramente una buena zona paramétrica para seleccionar:
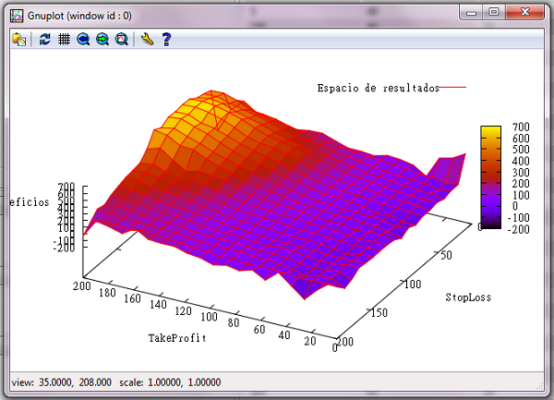
Cuando tenemos más de dos parámetros no podemos guiarnos visualmente pero podemos utilizar el algoritmo k-means clustering para que clasifique en grupos (clusters) todos los conjuntos de parámetros . De esta forma se obtienen conjuntos muy robustos que en forward test arrojan mejores resultados que otros conjuntos elegidos mediante métodos menos rigurosos.
Sistemas basados en Redes Neuronales
La Wikipedia define las redes neuronales como un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de conexión de neuronas que colaboran entre sí para producir un estímulo de salida.
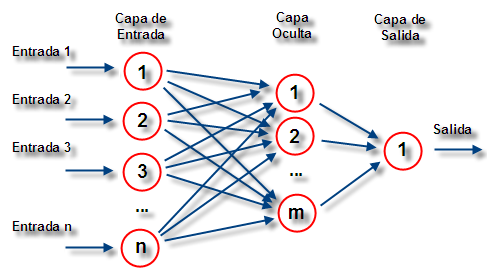
Las redes neuronales son uno de los modelos de Machine Learning más comunmente aplicados.
Como los otros modelos la red neuronal necesita una serie de datos de entrada que podrían ser por ejemplo: la variación de los precios de cierre las últimas sesiones, los puntos de pivote diario, el volumen operado, etc. Además de estos datos le proporcionaremos si la sesión cerró alcista o bajista y con esto la entrenaremos.
Después le daremos una nueva serie de datos de sesiones donde no le decimos si cerró al alza o a la baja pero sí los otros datos (precios de cierre, puntos pivote, volumen, etc), la red tratará de predecir cómo fue el cierre de sesión y nos dará por cada sesión un valor de confianza para la predicción alcista y otro para la predicción bajista. Tomando el valor más alto tendremos la predicción.
En la figura 3 se muestra la curva de balance de un sistema de redes neuronales para el EURUSD en velas de 1 hora. Para cada predicción con una confianza mayor de 0,5.
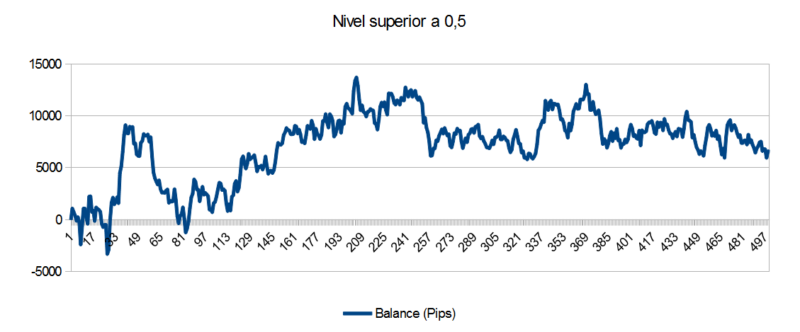
Como se ve, una red neuronal bien entrenada puede ofrecer muy buenos resultados. Este sistema logró unos 6000 pips en unos 20 días de trading aproximadamente.
Pero como decíamos la segunda característica de los modelos de Machine Learning es que al ofrecer niveles de predicción sus señales pueden ser filtradas y no operar a menos que se supere determinado umbral. Veamos en la figura 4 lo que sucede cuando exigimos al modelo que su predicción alcista o bajista tenga un valor de confianza mayor a 0,55 para abrir una nueva posición, cerrando además cualquier posición abierta cuando la nueva predicción no supere este nivel.
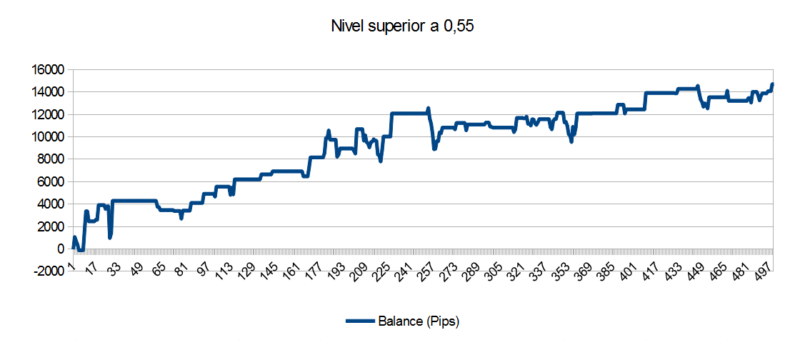
Como era de esperar hemos reducido el número de trades, pero además aumentado el beneficio y disminuido el tamaño de los retrocesos.
De esta forma un mismo modelo puede aplicarse de diferentes formas en función del perfil de riesgo de un inversor determinado.
Conclusión
Los sistemas basados en modelos de Machine Learning dotan al trader de nuevo arsenal para la batalla en los mercados y le ofrecen una ventaja excepcional frente a los otros traders que no utilizan esta tecnología.