
- Descubrirás por qué elegir bien tus datos al operar con CFDs es más importante que tu estrategia.
- Artículo publicado en Hispatrading Magazine 63.
Un solo cambio en la fuente puede convertir una estrategia ganadora en un fracaso.
Cuando desarrollé mi primera estrategia de trading con CFDs en Forex, me estrellé contra una realidad que nadie me había advertido: en los mercados OTC no existe un precio «oficial». Cada proveedor presentaba su propia versión de la realidad, con diferencias que transformaban una estrategia ganadora en perdedora con solo cambiar la fuente de los datos.
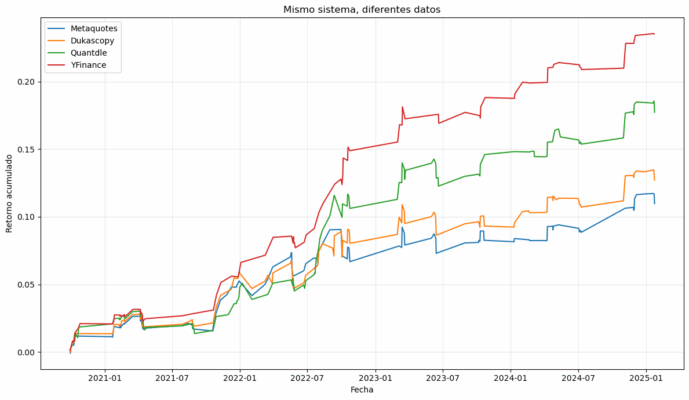
Este problema no es exclusivamente mío, afecta a todos los que operamos con CFDs. Déjame compartirte mi viaje hacia la búsqueda de datos fiables y los obstáculos que encontré en cada etapa.
La escasez de los datos del broker
Comencé con lo que parecía más lógico: utilizar los datos de mi propio broker. Al fin y al cabo, reflejan las condiciones reales contra las que ejecutaría mis órdenes. La decepción llegó rápido: el histórico disponible apenas cubría unos pocos años.
Esta limitación resultó crítica. ¿Cómo podía probar mi estrategia en diferentes ciclos de mercado con datos que apenas cubrían unos años?
La trampa de MetaQuotes
Ante la escasez de datos históricos, MetaTrader ofrece la posibilidad de descargar más datos. Sin embargo, esta opción muestra una advertencia reveladora:
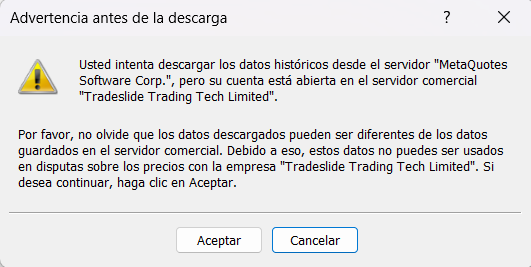
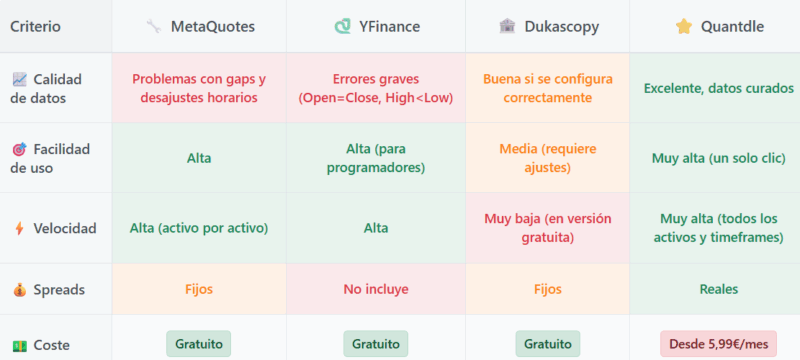
Ignoré la advertencia inicialmente y utilicé los datos de MetaQuotes que ofrece MetaQuotes, hasta que empecé a notar patrones extraños en mis backtests. Descubrí gaps inexplicables y desajustes horarios (especialmente evidentes durante los cambios estacionales) que distorsionaban completamente los resultados. Lo que parecía una solución conveniente resultó ser una puerta abierta a la imprecisión.
Las alternativas gratuitas
Decidí explorar YFinance, una biblioteca gratuita que parecía prometedora. Sin embargo, tras varios backtests fallidos, analicé los datos con detalle y encontré errores alarmantes: numerosas velas donde Open=Close (alterando gravemente el cálculo de indicadores técnicos) y ocasionalmente contradicciones donde High < Low.
No me rendí y probé con Dukascopy a través de QuantDataManager. La calidad parecía mejor, pero el proceso resultó exasperante: necesitaba configurar manualmente los ajustes horarios y descargar activo por activo, con una lentitud que convertía cada actualización en una tarea de horas.
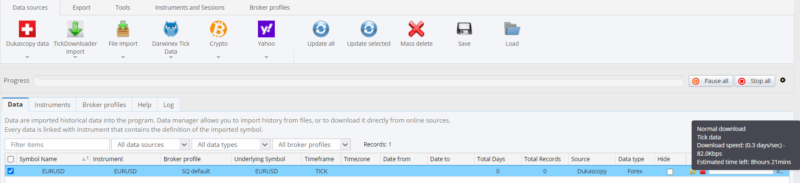
En busca de soluciones
Tras los intentos fallidos, comprendí que estaba enfocando el problema incorrectamente. En lugar de datos gratuitos, lo que necesitaba eran datos fiables, consistentes y fáciles de mantener actualizados. Comencé a evaluar diferentes proveedores especializados, poniendo especial atención en:
- Profundidad histórica (¿desde cuándo están disponibles los datos?)
- Calidad (¿presentan gaps o anomalías?)
- Precisión (¿incluyen información realista sobre spreads?)
- Usabilidad (¿cómo de complejo es mantenerlos actualizados?)
Mi elección personal: calidad y practicidad
Tras evaluar múltiples alternativas, encontré en Quantdle una solución que, para mis necesidades específicas, equilibra calidad y facilidad de uso. El coste mensual, aunque menor, es un handicap respecto a otras opciones gratuitas, pero el tiempo ahorrado en configuraciones y descargas y la fiabilidad de los datos lo justifican.
Lo que realmente me convenció fue la capacidad de actualizar todos los históricos en MT5 mediante un simple EA, eliminando el tedioso proceso manual que había experimentado con otras opciones.
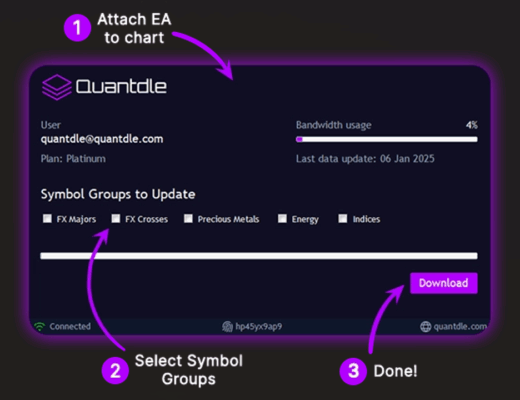
Los datos están disponibles desde 2004, lo que me permite probar mis estrategias a través de diferentes ciclos económicos, incluyendo la crisis de 2008 y la volatilidad de la pandemia.
El aspecto de los spreads reales ha sido particularmente valioso para mis simulaciones, aunque reconozco que para estrategias que no dependan tanto de la precisión de los spreads, esta característica puede ser menos crítica.
No es una solución perfecta para todos – traders con presupuestos muy limitados pueden preferir invertir tiempo en configurar manualmente opciones como la de Dukascopy a través de QuantDataManager – pero para mi flujo de trabajo actual, la relación tiempo-calidad-coste es óptima.
La lección aprendida
Mi experiencia me ha enseñado que la elección de datos no es un detalle técnico sino una decisión estratégica fundamental. El tiempo perdido desarrollando sistemas sobre datos deficientes, las decisiones equivocadas basadas en backtests engañosos y las estrategias mal calibradas tienen un coste real que supera con creces la inversión en una fuente fiable.
Para quienes nos tomamos el trading en serio, los datos son la materia prima esencial. Como en cualquier construcción, si los cimientos no son sólidos, todo lo que construyamos encima estará en riesgo, independientemente de lo sofisticado que sea nuestro sistema.
Recomendaciones prácticas
Si estás comenzando tu camino en el trading algorítmico, te sugiero considerar estos factores antes de elegir una fuente de datos:
Consistencia temporal
Verifica que no existan saltos temporales inexplicables o periodos sin datos. Estos vacíos pueden distorsionar completamente los indicadores que dependan de series temporales continuas, como medias móviles o cálculos de volatilidad histórica.
Coherencia de precios
Examina manualmente algunas secciones de los datos para identificar anomalías como velas donde el precio más alto sea inferior al más bajo, o situaciones donde todos los precios de apertura y cierre coincidan artificialmente durante periodos prolongados.
Ajustes horarios
Los cambios de horario estacionales pueden crear duplicaciones o vacíos en tus datos. Un buen proveedor debería manejar estos cambios sin crear artefactos que puedan disparar señales falsas en tu sistema.
Realismo en los spreads
Para simulaciones verdaderamente representativas, necesitas datos que reflejen los spreads reales en diferentes condiciones de mercado, especialmente durante periodos de alta volatilidad cuando los spreads suelen ampliarse significativamente.
La calidad de los datos determina la calidad de tus decisiones. En un entorno donde cada pip cuenta, partir de información imprecisa es comenzar la carrera con una desventaja que ninguna optimización posterior podrá compensar completamente.