![]()
La aplicación de datos alternativos es actualmente una fuerte tendencia en la industria de inversión. Nosotros también analizamos algunos conjuntos de datos en el pasado, ya sean datos ESG, sentimiento o presentaciones de empresas. Este artículo continúa la exploración del espacio de datos alternativos. Esta vez, utilizamos el trabajo de investigación de Joenväärä, que muestra que los fondos de cobertura léxicamente diversos superan a los léxicamente homogéneos como inspiración para que analicemos varias métricas léxicas en los informes 10-K y 10-Q. Una vez más, mostramos que tiene sentido transmitir ideas de un trabajo de investigación a una clase de activos completamente diferente.
Introducción
La invención de la máquina de vapor en 1698 marca el comienzo de la primera revolución industrial. Desde entonces, hemos logrado un progreso significativo y parece que no estamos disminuyendo la velocidad. Algunos dicen que la Inteligencia Artificial (IA) marca el comienzo de la revolución industrial más reciente.
La inteligencia artificial se convirtió en un tema candente en los últimos años debido a su variedad de funciones, incluido el reconocimiento de voz y lenguaje. El procesamiento del lenguaje natural, o NLP para abreviar, es la capacidad de un programa para comprender el lenguaje humano. Podría preguntarse, ¿cómo es esto útil en el ámbito financiero? Pues bien, existen numerosos trabajos de investigación ( Banker, 2021 y Joenväärä, 2019) que analizan la conexión entre el vocabulario de los inversores y la rentabilidad de sus estrategias.
Específicamente, la investigación de Joenväärä, 2019 nos inspiró a analizar varias métricas léxicas en los informes 10-K y 10-Q. Después de ajustarlos por riesgo, encontraron que los fondos de cobertura léxicamente diversos superan a los fondos de cobertura léxicamente homogéneos. Además, explican que los inversores reaccionan correctamente, pero no del todo, a la información sobre la habilidad de los gestores de fondos integrada en la diversidad léxica. Sus resultados respaldan la idea de que las habilidades lingüísticas son útiles para el rendimiento de las inversiones.
Además, los datos alternativos se están convirtiendo en un tema principal en la gestión de inversiones y el comercio algorítmico. Por ejemplo, el análisis textual de las presentaciones 10-K y 10-Q se puede utilizar como parte rentable de las carteras de inversión ( Padysak, 2020). Todas las empresas que cotizan en bolsa deben presentar informes 10-K y 10-Q periódicamente. Estos informes consisten en información relevante sobre el desempeño financiero. Hoy en día, hay un cambio gradual de la información numérica a la basada en texto, lo que hace que los informes sean más difíciles de analizar ( Cohen , 2010). Aún así, los informes 10-K y 10-Q reciben un gran interés por parte de académicos, inversores y analistas.
Datos
BRAIN es una de las empresas que analiza los informes 10-K y 10-Q utilizando PNL. El principal objetivo del conjunto de datos Brain Language Metrics on Company Filings (BLMCF) es monitorear numerosas métricas de idioma en informes de empresas 10-Ks y 10-Qs para aproximadamente más de 6000 acciones estadounidenses. El conjunto de datos BLMCF consta de dos partes. La primera parte contiene las métricas de idioma del informe 10-K o 10-Q más reciente para cada empresa, como:
- sentimiento financiero
- Porcentaje de palabras pertenecientes al dominio financiero clasificadas por tipos de lengua:
- Lenguaje «restrictivo»
- Lenguaje «interesante»
- Lenguaje “litigioso”
- Lenguaje de “incertidumbre”
- Puntuación de legibilidad
- Métricas léxicas como densidad y riqueza léxica
- Estadísticas de texto, como la longitud del informe y la longitud promedio de la oración
La segunda parte incluye las diferencias entre los dos informes 10-Ks o 10-Qs más recientes del mismo período para cada empresa.
Este artículo se centra en la primera sección del conjunto de datos BLMCF, específicamente las métricas léxicas como la riqueza léxica, la densidad léxica y la densidad específica .
En palabras simples, la riqueza léxica dice cuántas palabras únicas usa el autor. La idea es que cuanto más variado sea el vocabulario del autor, más complejo será el texto. La riqueza léxica se mide por el Type-Token Ratio (TTR), que se define como el número de palabras únicas dividido por el número total de palabras. Como resultado, cuanto mayor sea el TTR, mayor será la complejidad léxica.
En segundo lugar, la densidad léxica mide la estructura y complejidad de la comunicación humana en un texto. Una densidad léxica alta indica una gran cantidad de palabras portadoras de información, y una densidad léxica baja indica relativamente pocas palabras portadoras de información. La densidad léxica se calcula como el número de los llamados tokens léxicos (verbos, sustantivos, adjetivos, verbos excepto verbos auxiliares) dividido por el número total de tokens.
Por último, la densidad específica mide qué tan denso es el lenguaje del informe desde un punto de vista financiero. BRAIN utiliza un diccionario de palabras financieramente relevantes como referencia. Luego, la densidad específica se calcula como la relación entre el número de palabras del diccionario presentes en el informe dividido por el número total de palabras.
Análisis
Este artículo analiza cómo la riqueza léxica, la densidad léxica, la densidad específica y sus combinaciones afectan los retornos de la estrategia. Creamos dos universos de inversión, el primero contiene las 500 acciones principales por capitalización de mercado de las bolsas NYSE, NASDAQ y AMEX, y el segundo contiene las 3000 acciones principales. El primer universo de inversión es altamente líquido y contiene solo acciones de gran capitalización. El segundo universo de inversión está formado por acciones de grande, media y pequeña capitalización. Nuestro proceso para crear una cartera de factores de inversión consiste en clasificar las acciones en deciles (quintiles) y crear una estrategia de factor de renta variable largo-corto (decil superior largo, decil inferior corto). Todos los backtests se realizan en la plataforma Quantconnect, y los datos se integran en la propia plataforma. Además, se puede encontrar aquí: https://www.quantconnect.com/datasets/brain-language-metrics-company-filings.
Las estrategias de factores sugeridas se reequilibran mensualmente y utilizamos diferenciales de oferta y demanda históricos reales (deslizamiento). Se omiten los costos de negociación (comisiones de transacción); sin embargo, no tienen un gran impacto en la estrategia resultante, ya que el gestor de activos habitual puede lograr costos en el rango de 1-2 puntos básicos por operación.
Sospechamos que la densidad léxica y la densidad específica tienen el mayor efecto en el retorno. Esto significaría que cuantas más palabras portadoras de información y más palabras relacionadas con las finanzas tenga el informe, mejor será el comportamiento de la empresa.
¿Cómo se ve la estrategia factorial resultante?
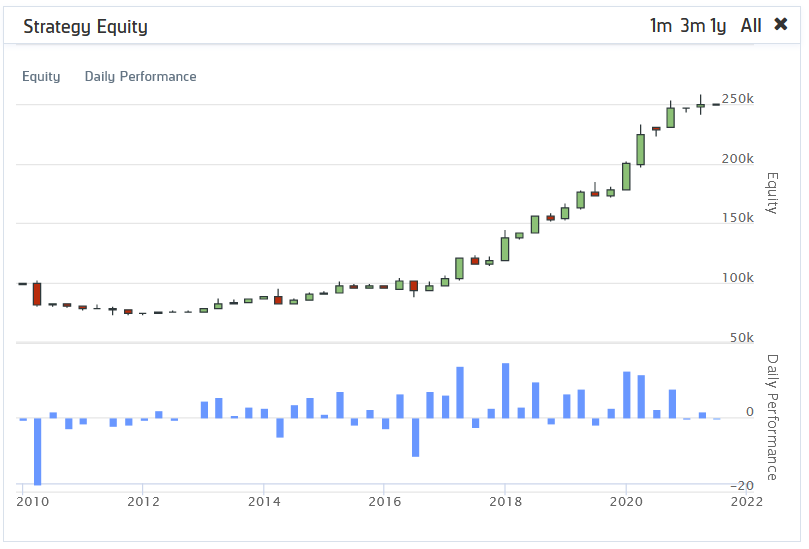
Pero primero, analicemos las tres métricas léxicas por sí mismas. Echemos un vistazo a la estrategia basada puramente en la riqueza léxica. La primera figura muestra los resultados para el universo de inversión más pequeño que contiene 500 acciones. Como podemos ver en el gráfico, el rendimiento no es tan bueno. La tendencia está creciendo sólo en los últimos años. El ratio de Sharpe de esta estrategia es -0,053.
Sin embargo, cuando ampliamos el universo de inversión a 3000 acciones, el rendimiento mejora. Así, aunque el rendimiento no es perfecto, es mucho mejor que el escenario anterior. Además, el ratio de Sharpe crece de -0,053 a 0,21.
Ahora echemos un vistazo a la segunda métrica léxica: densidad léxica. Analizamos esta estrategia en el universo de inversión más pequeño que contiene 500 acciones. Como podemos ver, la tendencia del rendimiento es creciente desde 2012. El rendimiento negativo durante los primeros años puede explicarse por el tamaño y la precisión del conjunto de datos BRAIN en los primeros años. El ratio de Sharpe de esta estrategia es 0,362.
La tercera estrategia que analizamos se basa en la densidad específica . Al igual que antes, analizamos esta estrategia en el universo de inversión más pequeño que contiene 500 acciones. Como podemos ver, la tendencia del rendimiento acumulado es creciente casi desde el principio. Esta estrategia está experimentando reducciones significativas solo en los últimos años, lo que puede explicarse por la pandemia de COVID-19. El ratio de Sharpe de esta estrategia es 0,416.
En general, argumentamos que la riqueza léxica tiene un efecto mucho más débil sobre el rendimiento que la densidad léxica o la densidad específica. Así, en la siguiente sección, analizamos la combinación de densidad léxica y densidad específica. Analizamos esta estrategia en el universo de inversión que contiene 500 acciones. Como podemos ver, el rendimiento acumulado de esta estrategia está aumentando durante casi todo el período. El ratio Sharpe de la estrategia que combina las dos métricas es 0,688.
En conjunto, la estrategia combinada de factor largo-corto de densidad léxica y específica ofrece resultados realmente prometedores. El único período con un rendimiento ligeramente negativo es al comienzo de la muestra en 2012. Podemos especular e intentar explicar esto por el hecho de que el conjunto de datos BRAIN era nuevo. A menudo, en conjuntos de datos alternativos, el comienzo de la serie temporal es más problemático y está menos cubierto que años posteriores, aunque no tenemos evidencia específica de esto para el conjunto de datos BRAIN.
¿Cuál es el impulsor fundamental de esta estrategia de factores? Por lo que hemos encontrado, parece que, en promedio, las empresas con un estilo de informes más «denso» tienden a obtener mejores resultados. Podría deberse a que los informes 10K y 10Q serían menos inciertos y más «reales» y serían recompensados por una mayor afluencia de inversores. También significaría que la estrategia está conectada con estrategias «basadas en devengo», donde las empresas con estados financieros menos opacos superan a aquellas con prácticas contables menos transparentes.
Autores:
Daniela Hanicová , analista de Quant, Quantpedia.com
Filip Kalus , desarrollador de TI/creador de código de QuantConnect, Quantpedia.com
Radovan Vojtko , director ejecutivo y director de investigación, Quantpedia.com