![]()
Los estudios que utilizan técnicas de aprendizaje automático para la previsión de rendimientos han demostrado ser prometedores. Sin embargo, al igual que en la fijación de precios de activos empíricos, los investigadores se enfrentan a numerosas decisiones sobre métodos de muestreo y la estimación de modelos. Esto plantea una pregunta importante: ¿cómo afectan estas opciones metodológicas al rendimiento de las estrategias de trading basadas en ML? Investigaciones recientes de Vaibhav, Vedprakash y Varun demuestran que incluso las decisiones pequeñas pueden afectar significativamente el rendimiento general. Parece que en el aprendizaje automático, el viejo adagio también es cierto: el diablo está en los detalles.
Este sencillo documento es un excelente recordatorio de que las decisiones metodológicas en las estrategias de aprendizaje automático (ML) (como el uso de la ponderación EW o VW, incluidos los micro topes, etc.) afectan significativamente los resultados. Es crucial considerar estas decisiones como estrategias tradicionales de factores transversales, y los profesionales como los gerentes de cartera siempre deben tener esto en cuenta antes de implementar dicha estrategia.
Las nuevas integraciones de las técnicas de IA (inteligencia artificial) y aprendizaje profundo (DL) en los modelos de fijación de precios de activos han despertado un nuevo interés en la academia y la industria financiera. Aprovechando el inmenso poder computacional de las GPU, estos modelos avanzados pueden analizar grandes cantidades de datos financieros con una velocidad y precisión sin precedentes. Esto ha permitido una previsión de rendimiento más precisa y ha permitido a los investigadores abordar incertidumbres metodológicas que antes eran difíciles de abordar.
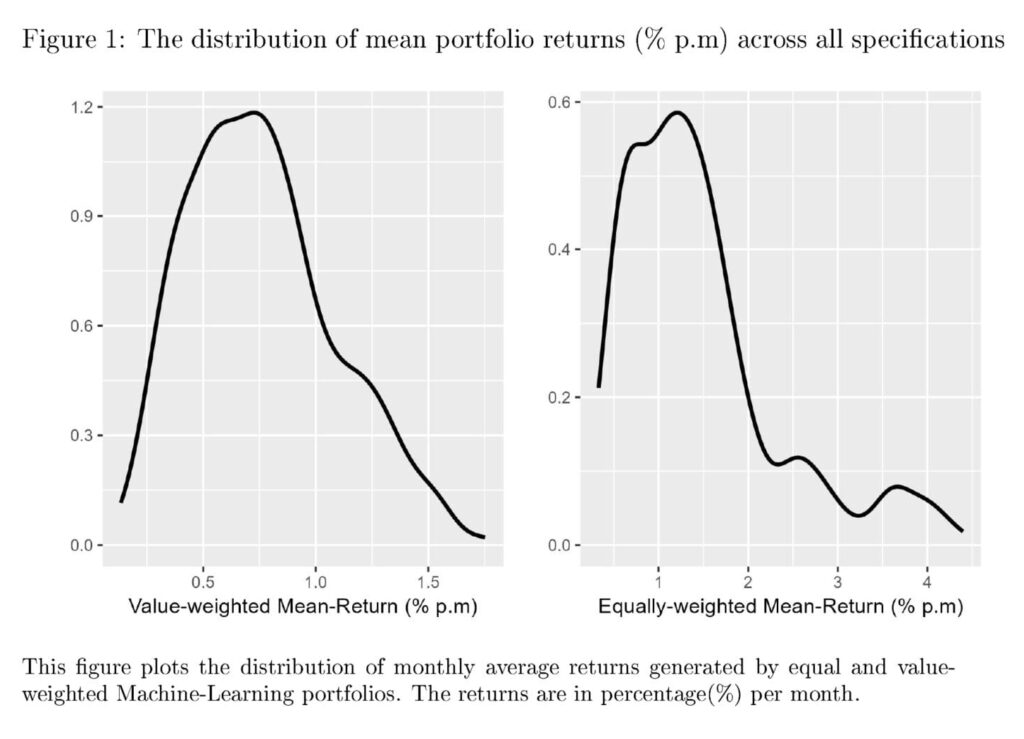
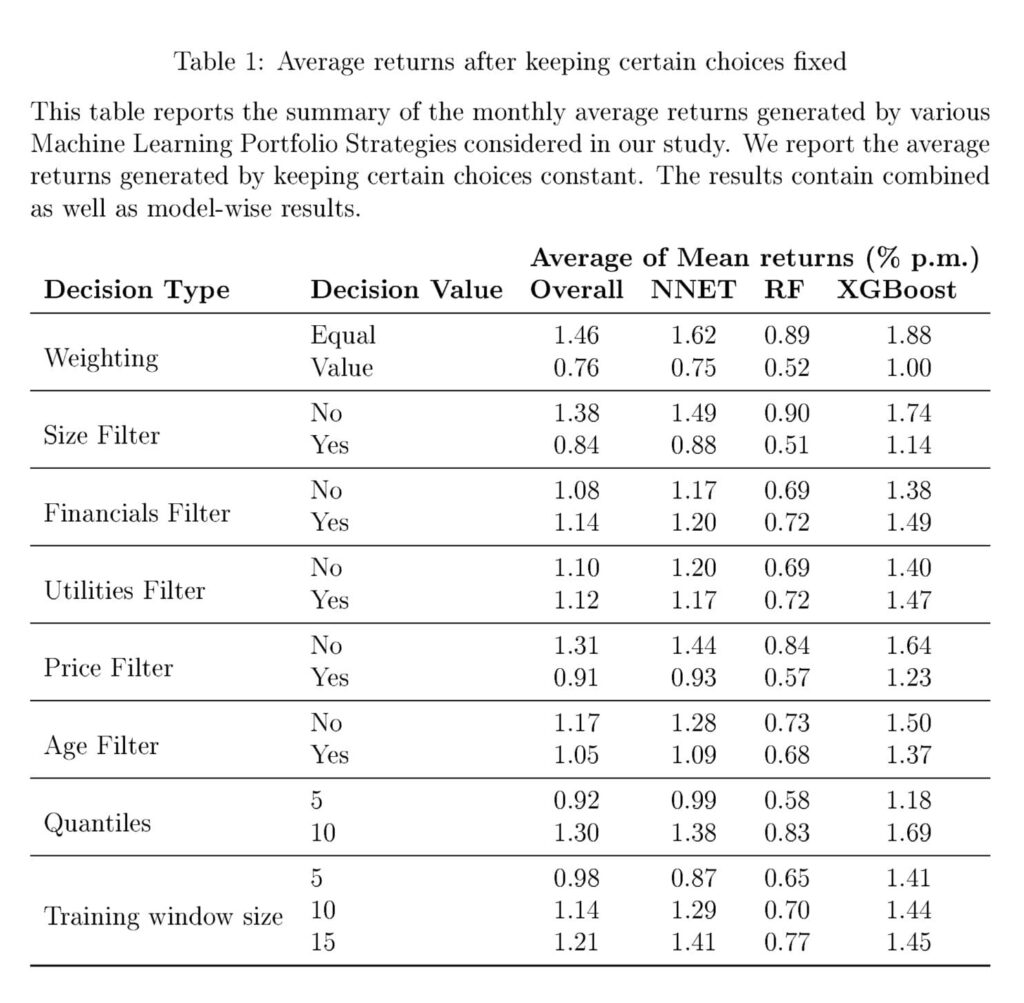
Los resultados de más de 1152 combinaciones de elección muestran una variación considerable en los rendimientos promedio de las estrategias de ML. El uso de carteras ponderadas por valor con filtros de tamaño puede frenar una buena parte de esta variación, pero no puede eliminarla. Entonces, ¿cuál es la solución a los errores no estándar? Los estudios sobre la fijación de precios de activos empíricos han propuesto varias soluciones. Mientras que Soebhag et al. (2023) sugieren que los investigadores pueden mostrar resultados a través de las principales opciones de especificación, Walter et al. (2023) argumentan a favor de informar toda la distribución en todas las especificaciones.
Si bien los autores de este documento están de acuerdo con los resultados de informes a través de variaciones, es aconsejable recomendar una solución única para este problema. A pesar de una extensa carga de cálculo, es posible calcular e informar la distribución completa de los rendimientos de las carteras ordenadas por características, como en Walter et al. (2023). Sin embargo, cuando se utilizan métodos de aprendizaje automático, la documentación de la distribución en su conjunto probablemente impondrá una carga computacional extrema para el investigador. Aunque una distribución completa es más informativa que una parcial, los costos y beneficios de ambas opciones deben evaluarse antes de dar recomendaciones generalizadas.
¿Cuáles son las formas adicionales de controlar la variación metodológica mientras se impone una carga modesta al investigador? Las recomendaciones comunes favorecen la identificación de primero las opciones de alto impacto (por ejemplo, filtros de ponderación y tamaño) en un análisis a menor escala. Los investigadores pueden entonces, como mínimo, informar variaciones de los resultados a través de especificaciones de alta prioridad mientras mantienen el resto opcional.
Autores: Vaibhav Lalwani, Vedprakash Meshram y Varun Jindal
Título: El impacto de las opciones metodológicas en las carteras de aprendizaje automático
Enlace: https://papers.ssrn.com/sol3/papers.cfm? abstract_id=4837337
Resumen:
Exploramos el impacto de las decisiones metodológicas en la rentabilidad de las estrategias de inversión basadas en machine learning. Los resultados de 1152 estrategias muestran que las decisiones metodológicas inducen una variación considerable en los rendimientos de las estrategias. Los errores no estándar de las estrategias de machine learning suelen ser mayores que los errores estándar y permanecen significativos incluso después de controlar algunas decisiones de alto impacto. Aunque la eliminación de micro-capitalizaciones y el uso de portafolios ponderados por valor reducen los errores no estándar, su tamaño sigue siendo cuantitativamente comparable a los errores estándar tradicionales.
Como siempre, presentamos varias figuras y tablas emocionantes:
Citas notables del artículo de investigación académica:
“[H]ay amplia evidencia que sugiere que los investigadores pueden usar herramientas de ML para desarrollar mejores modelos de previsión de retornos. Sin embargo, un investigador necesita tomar ciertas decisiones al usar machine learning en la previsión de retornos. Estas decisiones incluyen, pero no se limitan a, el tamaño de las ventanas de entrenamiento y validación, la variable de resultado, el filtrado de datos, la ponderación y el conjunto de variables predictoras. En un caso de ejemplo con 10 variables de decisión, cada una ofreciendo dos caminos, las especificaciones totales son 2^10, es decir, 1024. Incluir decisiones más complejas puede llevar a miles de posibles caminos que el diseño de investigación podría tomar. Aunque la mayoría de los estudios integran algún nivel de pruebas de robustez, mantenerse al día con todo el universo de posibilidades es prácticamente imposible. Además, debido a la naturaleza computacionalmente intensiva de las tareas de machine learning, es extremadamente difícil explorar el impacto de todas estas decisiones, incluso si un investigador lo desea. Por lo tanto, algunas de estas decisiones suelen quedar a criterio del investigador.Aunque la sensibilidad de los hallazgos a incluso decisiones empíricas aparentemente inofensivas está bien reconocida en la literatura¹, solo recientemente hemos comenzado a reconocer la magnitud del problema. Menkveld et al. (2024) acuñan el término errores no estándar para denotar la incertidumbre en las estimaciones debido a diferentes elecciones metodológicas. Estudios como Soebhag et al. (2023), Walter et al. (2023) y Fieberg et al. (2024) muestran que los errores no estándar pueden ser tan grandes, si no mayores, que los errores estándar tradicionales. Este fenómeno plantea importantes preguntas sobre la reproducibilidad y fiabilidad de la investigación financiera. Subraya la necesidad de un enfoque posiblemente más sistemático en la elección de especificaciones metodológicas y la importancia de la transparencia al reportar metodologías y resultados de investigación.Dado que incluso elecciones aparentemente inocuas pueden tener un impacto significativo en los resultados finales, a menos que realicemos un análisis formal de todas (o al menos la mayoría) las elecciones del diseño juntas, será difícil saber qué decisiones importan y cuáles no mediante pura intuición.Incluso en estudios sobre fijación de precios de activos que utilizan una sola característica para clasificar, hay miles de posibles elecciones (Walter et al., 2023 utilizan hasta 69,120 especificaciones potenciales). Al extender el análisis a portafolios basados en machine learning, la lista posible de elecciones (y su posible impacto) se expande aún más. Los usuarios de machine learning deben tomar muchas decisiones adicionales para modelar la relación entre los retornos y las características predictoras. Con el número creciente de modelos disponibles (ver Gu et al., 2020 para un subconjunto), no sería injusto decir que los académicos en este campo están abrumados por las opciones disponibles.Como argumentan Harvey (2017) y Coqueret (2023), tal cantidad enorme de opciones podría exacerbar el sesgo hacia la publicación de resultados positivos.
El interés por las aplicaciones del Machine Learning en Finanzas ha crecido sustancialmente en la última década o más. Desde el trabajo seminal de Gu et al. (2020), se han utilizado muchas variantes de modelos basados en machine learning para predecir retornos sobre activos. Nuestra segunda contribución es a este creciente cuerpo literario. Se entiende bien que hay muchas decisiones al usar ML en la previsión de retornos. Pero ¿son las diferencias entre especificaciones lo suficientemente grandes como para justificar precaución? Avramov et al. (2023) muestra que eliminar ciertos tipos de acciones reduce considerablemente el rendimiento de las estrategias basadas en ML.Ampliamos esta línea de pensamiento utilizando un conjunto más amplio de opciones que incluye varias consideraciones que hasta ahora los investigadores podrían haber ignorado. Al proporcionar una comprensión general del panorama sobre cómo varía el rendimiento de las estrategias basadas en ML según los caminos decisionales tomados, realizamos una especie de análisis a gran escala sobre la sensibilidad y eficacia del machine learning en la previsión del retorno.Además, al analizar sistemáticamente los efectos de diversas elecciones metodológicas, podemos entender cuáles son los factores más influyentes para determinar el éxito o fracaso de una estrategia basada en ML.
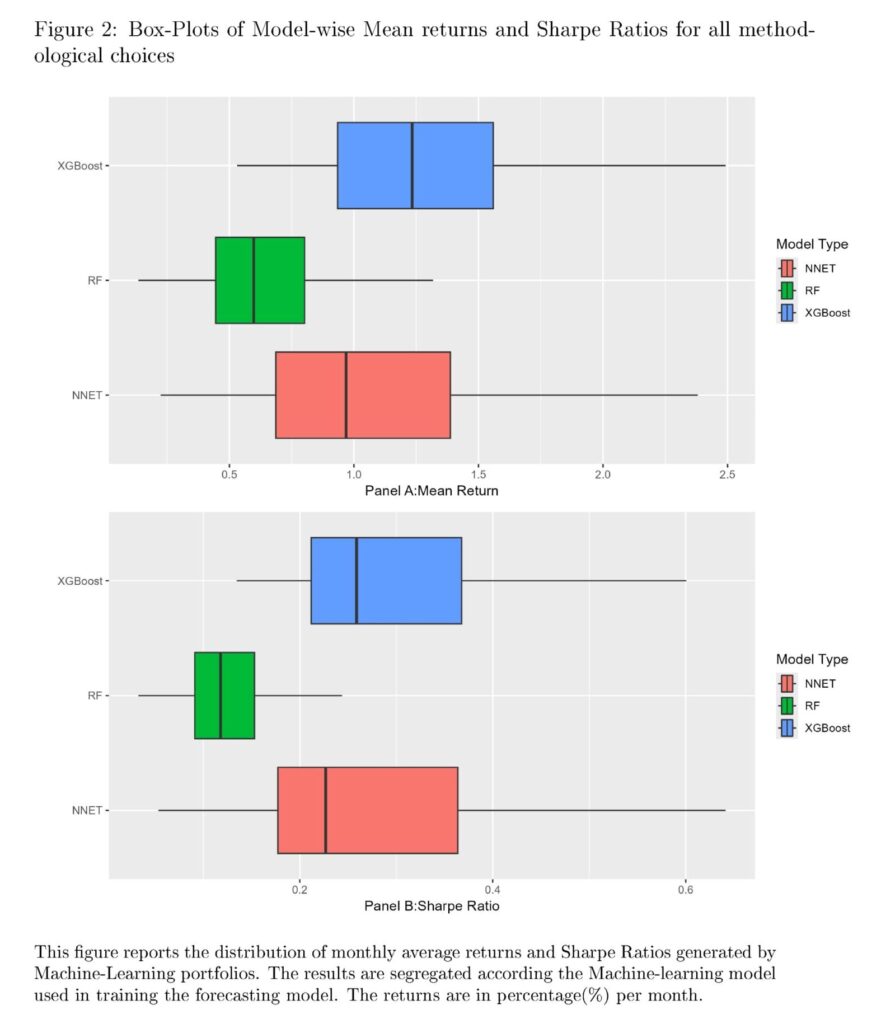
Para resumir, encontramos que las decisiones respecto a la inclusión o exclusión de micro-capitalizaciones y acciones baratas, así como la ponderación aplicada a las acciones tienen un impacto significativo en los rendimientos promedio. Además, un aumento en la longitud del período muestral mejora el rendimiento general; sin embargo, no se necesitan ventanas grandes para estrategias basadas en Boosting.
Según nuestros resultados, argumentamos que los sectores financieros y servicios públicos no deberían ser excluidos del muestreo cuando se usa machine learning. Algunas elecciones metodológicas pueden reducir la variación metodológica alrededor del rendimiento estratégico; sin embargo, los errores no estándar siguen siendo considerables.”