![]()
A fines de 2018, los investigadores de Google AI Language lograron un avance significativo en la comunidad de aprendizaje profundo Depp Learning. La nueva técnica para el Procesamiento del lenguaje natural (NLP) llamada BERT (Representaciones de codificador bidireccional de transformadores) era de código abierto. El rendimiento increíble del algoritmo BERT es impresionante. BERT probablemente estará presente por mucho tiempo. Por lo tanto, es útil repasar los conceptos básicos de esta notable parte de la familia de algoritmos de aprendizaje profundo. [ 1 ]
En 2018, Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova publicaron el modelo de lenguaje enmascarado: Representaciones de codificador bidireccional de transformadores (BERT). El artículo se llama simplemente: “BERT: Pre-entrenamiento de Transformadores Bidireccionales Profundos para la Comprensión del Lenguaje” . A la fecha, esta publicación cuenta con más de 60.000 citas. En 2021, se publicó una encuesta que demostró que BERT se ha convertido en una base compleja en los experimentos de procesamiento de lenguaje natural (NPL). [2]
Transformador (modelo de aprendizaje automático)
Los modelos basados en transformadores han mejorado significativamente las etapas más recientes en el desarrollo de múltiples áreas de la PNL. Sin embargo, la comprensión de lo que está detrás del éxito y la funcionalidad de NPL aún es limitada. [2] El transformador se define como “un modelo de aprendizaje profundo que adopta el mecanismo de autoatención, ponderando diferencialmente el significado de cada parte de los datos de entrada”. Se utiliza ampliamente en las disciplinas de visión por computadora (CV) y procesamiento de lenguaje natural (NLP). [ 3 ]

PNL – Procesamiento del Lenguaje Natural
El método automatizado de análisis de texto de enfoque computarizado, conocido como procesamiento del lenguaje natural (NLP), se basa en varias teorías y tecnologías. Es un área muy activa de investigación y desarrollo, por lo que no existe una sola definición acordada que satisfaga a todos. Hay ciertos aspectos, que serían parte de la definición. La definición: “El procesamiento del lenguaje natural es una gama de técnicas computacionales teóricamente motivadas para analizar y representar textos de origen natural en uno o más niveles de análisis lingüístico con el propósito de lograr un procesamiento del lenguaje similar al humano para una variedad de tareas o aplicaciones” . [4]
Definición de BERT
BERT es un marco para el aprendizaje automático que utiliza transformadores. El transformador es donde cada elemento de salida se vincula con cada componente de entrada y se asignan pesos para establecer sus respectivas relaciones. Esto se conoce como atención. BERT aprovecha la idea de entrenar previamente el modelo en un conjunto de datos más grande a través del modelado de lenguaje no supervisado. Al entrenar previamente en un gran conjunto de datos, el modelo puede comprender el contexto del texto de entrada. Posteriormente, al ajustar el modelo en datos supervisados específicos de la tarea, BERT puede lograr resultados prometedores.
En esta etapa, se pueden aplicar dos estrategias: ajuste fino y basado en funciones. ELMo (Incrustaciones de modelos de lenguaje, consulte Referencias relacionadas) utiliza el enfoque basado en características, donde la arquitectura del modelo es específica de la tarea. Esto significa que para cada tarea se utilizarán diferentes modelos y representaciones de lenguaje pre-entrenadas. Esto significa que para cada tarea se utilizarán diferentes modelos y representaciones de lenguaje pre-entrenadas.
El modelo BERT emplea codificadores transformadores bidireccionales y de ajuste fino para comprender el lenguaje, lo que le valió su nombre. Es crucial tener en cuenta que BERT es capaz de comprender el contexto completo de una palabra. BERT analiza las palabras que preceden y suceden a un término y determina su correlación.
A diferencia de otros modelos de lenguaje como Glove2Vec y Word2Vec, que crean incrustaciones de palabras sin contexto, BERT proporciona contexto mediante el uso de transformadores bidireccionales.
B = bidireccional.
A diferencia de los modelos anteriores, que eran unidireccionales y solo podían mover la ventana de contexto en una dirección, BERT utiliza un modelo de lenguaje bidireccional. Esto significa que BERT puede analizar la oración completa y moverse en cualquier dirección para comprender el contexto.
ER = Representaciones del codificador.
Cuando se ingresa un texto en un modelo de lenguaje, se codifica antes de ser procesado, y el resultado final también está en un formato cifrado que requiere descifrado. Este mecanismo de entrada y salida implica codificar la entrada y decodificar la salida, lo que permite que el modelo de lenguaje procese y analice de manera efectiva los datos de texto.
T = Transformadores
BERT utiliza transformadores y modelado de lenguaje enmascarado para el procesamiento de texto. Un desafío clave es identificar el contexto de una palabra en una posición particular, particularmente con pronombres. Para abordar esto, los transformadores prestan mucha atención a los pronombres y a la oración completa para comprender mejor el contexto. El modelado de lenguaje enmascarado también entra en juego, donde una palabra objetivo se enmascara para evitar la desviación del significado. Al enmascarar la palabra, BERT puede adivinar la palabra que falta con un ajuste fino.
Arquitectura modelo
La arquitectura modelo del BERT es fundamentalmente un codificador de transformador bidireccional multicapa basado en la implementación original descrita en Vaswani et al. (2017). [5]
La arquitectura del transformador consta de un codificador y un decodificador en un modelo de secuencia. El codificador se usa para incrustar la entrada, y el decodificador se usa para decodificar la salida incrustada nuevamente en una cadena. Este proceso es similar a los algoritmos de codificación y decodificación.
Sin embargo, la arquitectura BERT difiere de los transformadores tradicionales. El modelo apila codificadores uno encima del otro, según el caso de uso específico. Además, las incrustaciones de entrada se modifican y pasan a un clasificador específico de la tarea para su posterior procesamiento.

Figura 2 Diagrama de principio del modelo BERT para parámetros 110M y parámetros 340M. [ 6 ]
Los tokens en BERT se utilizan para representar palabras y subpalabras en el texto de entrada. A cada token se le asigna una representación o incrustación de vector de dimensión fija. Estas incrustaciones se utilizan para capturar la relación contextual entre las palabras en el texto de entrada. Mediante el uso de tokens, BERT puede procesar texto de una manera que captura el significado y el contexto de palabras y frases, en lugar de solo sus representaciones aisladas. Esto permite a BERT realizar una amplia gama de tareas de procesamiento de lenguaje natural con gran precisión. [ 12 ]
Aquí hay algunos tokens utilizados en la arquitectura del modelo BERT NLP :
[ CLS ]: el token representa el comienzo de la oración y se usa para representar la secuencia de entrada completa para las tareas de clasificación.
[ SEP ]: el token se usa para separar dos oraciones o para separar la pregunta y la respuesta en tareas de preguntas y respuestas.
[ MAS K]: el token se usa para enmascarar una palabra durante el entrenamiento previo. También se utiliza durante el ajuste fino para predecir la palabra enmascarada.
[ UNK ] – token representa una palabra desconocida que no está presente en el vocabulario.
[ PAD ]: el token se usa como relleno para hacer que todas las secuencias de entrada tengan la misma longitud.
Aquí están los componentes y palabras relacionadas con BERT y sus definiciones [ 7 ]:
Parámetros : número de variables legibles o valores que están disponibles en el modelo.
Tamaño oculto : el tamaño oculto son las capas de funciones matemáticas entre la entrada y la salida. Asignará peso para producir el resultado deseado.
Capas de transformadores : número de bloques de transformadores. Un bloque transformador transformará una secuencia de representaciones de palabras en un texto contextualizado o una representación numérica.
Procesamiento : el tipo de unidad de procesamiento que se utiliza para entrenar el modelo.
Atención Jefes : el tamaño del bloque del transformador.
Duración del entrenamiento : tiempo que lleva entrenar el modelo.
Las partes principales de BERT y sus definiciones [ 12 ]:
| Parte | Definición |
| Tokenizador | El tokenizador de BERT toma texto sin procesar como entrada y lo divide en tokens individuales, que son las unidades básicas de texto utilizadas en NLP. |
| Incorporaciones de entrada | Una vez que el texto ha sido tokenizado, las incrustaciones de entrada de BERT asignan cada token a una representación vectorial de alta dimensión. Estos vectores capturan el significado de cada token en función de su contexto dentro de la oración. |
| codificador | BERT utiliza un codificador de transformador bidireccional multicapa para procesar las incorporaciones de entrada. El codificador consta de varias capas de transformadores apiladas, cada una de las cuales procesa las incorporaciones de entrada de forma diferente. |
| Encabezado LM enmascarada | El encabezado del modelo de lenguaje enmascarado (MLM) es una capa específica de tareas que está entrenada para predecir tokens enmascarados en la secuencia de entrada. Durante el entrenamiento previo, BERT enmascara aleatoriamente algunos de los tokens de entrada y entrena el modelo para predecir sus valores originales en función del contexto de los tokens circundantes. |
| Encabezado de predicción de la siguiente oración | El encabezado Predicción de la siguiente oración (NSP) es otra capa específica de la tarea que está entrenada para predecir si dos oraciones de entrada son consecutivas o no. Esto ayuda a BERT a capturar relaciones contextuales entre oraciones. |
| agrupador | Finalmente, el agrupador de BERT toma la salida de la última capa del transformador y produce una representación vectorial de longitud fija de la secuencia de entrada. Este vector se puede utilizar como entrada para tareas posteriores, como la clasificación o la regresión. |
El mecanismo de trabajo de BERT
Los siguientes pasos describen cómo funciona BERT.
- Datos de entrenamiento en grandes cantidades
BERT está diseñado para manejar una gran cantidad de palabras, lo que le permite aprovechar grandes conjuntos de datos para obtener un conocimiento completo del inglés y otros idiomas. Sin embargo, entrenar BERT en conjuntos de datos extensos puede llevar mucho tiempo. La arquitectura del transformador facilita el entrenamiento BERT y las unidades de procesamiento de tensores pueden acelerarlo. [ 7 ] [ 12 ]
- Modelo de lenguaje enmascarado
El aprendizaje bidireccional del texto es posible gracias a la técnica del Modelo de lenguaje enmascarado (MLM). Esto implica ocultar una palabra en una oración y pedirle a BERT que use las palabras en ambos lados de la palabra oculta de manera bidireccional para predecirla. En esencia, MLM le permite a BERT comprender el contexto de una palabra al considerar las palabras vecinas. [ 7 ] [ 12 ]
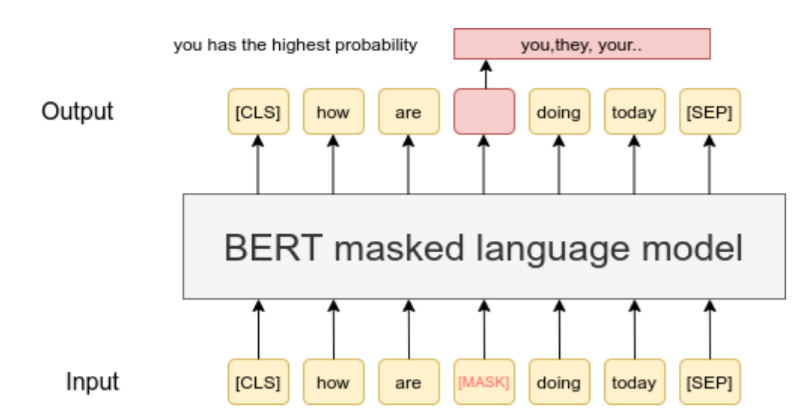
Figura 3 Oración BERT-Original «¿cómo estás hoy?». [9]
Al considerar la palabra contextualmente tanto antes como después del texto oculto, puede predecir con precisión la palabra que falta. El enfoque bidireccional utilizado en este proceso da como resultado el más alto nivel de precisión. Durante el entrenamiento, el 15% de las palabras tokenizadas se enmascaran aleatoriamente y el objetivo de BERT es predecir las palabras enmascaradas. [ 12 ]

Figura 4 Técnica del modelo de lenguaje enmascarado (MLM). [ 8 ]
3. Predicción de la siguiente oración
La predicción de la siguiente oración (NSP) es una técnica utilizada por BERT para comprender la relación entre las oraciones. Predice si una oración dada sigue a la anterior, aprendiendo así sobre el contexto del texto. Durante el entrenamiento, a BERT se le presenta una combinación de 50 % de pares de oraciones correctas y 50 % de oraciones emparejadas aleatoriamente para mejorar su precisión. [ 7 ] [ 12 ]
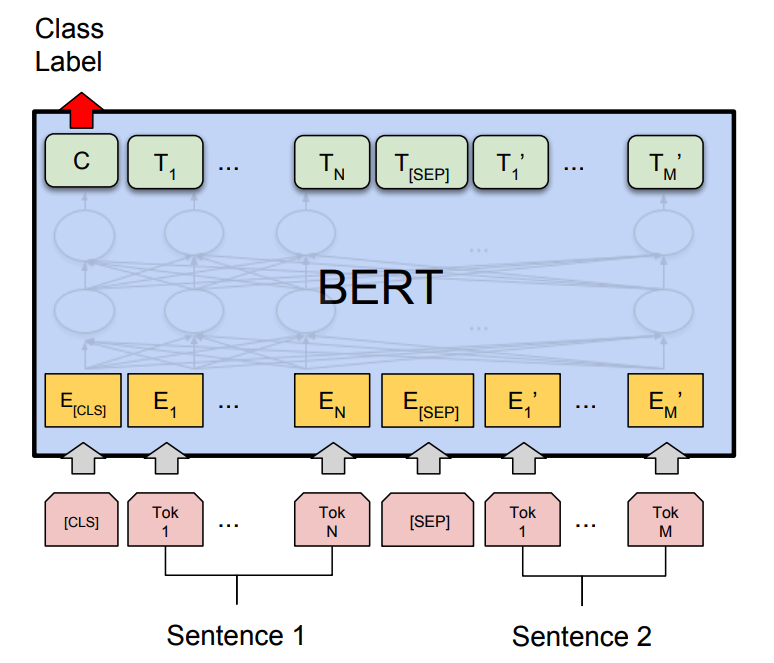
Figura 5 Técnica de predicción de la siguiente oración (NSP) [10]
- Transformadores
La arquitectura del transformador usa la atención , que paraleliza de manera eficiente el entrenamiento de aprendizaje automático y hace que sea factible entrenar BERT en datos de gran tamaño rápidamente. La atención es un algoritmo robusto de aprendizaje profundo que se vio por primera vez en los modelos de visión por computadora. Los transformadores crean pesos diferenciales enviando señales a las palabras críticas de una oración, evitando el desperdicio de recursos computacionales en información irrelevante.
Los transformadores aprovechan las capas de codificador y decodificador para procesar la entrada y predecir la salida, respectivamente. Estas capas se apilan una encima de la otra en una arquitectura de transformador. Los transformadores son particularmente adecuados para tareas de aprendizaje no supervisadas, ya que pueden procesar grandes cantidades de datos de manera eficiente.

Figura 6 La estructura codificador-decodificador de la arquitectura Transformer [ 14 ]
Algunas aplicaciones de BERT en PNL
Algunas de las aplicaciones del modelo de lenguaje BERT en NLP incluyen:
- Análisis de los sentimientos
- Traducción de idiomas
- Respuesta a preguntas
- Búsqueda de Google
- Resumen de texto
- Coincidencia y recuperación de texto
- Resaltado de párrafos.
Modelo BERT y su uso en el trading cuantitativo
En esta última sección del artículo, se ofrece una descripción general de algunos estudios recientes sobre el tema del modelo BERT en el análisis cuantitativo. Los documentos de lectura adicional siempre están vinculados debajo del título.
Giro del mercado de la noche a la mañana y la reacción asimétrica a las noticias
Enlace: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4307675
En este estudio, los autores se centraron en la información contenida en las noticias financieras y su impacto en el mercado de valores de EE. UU. Estudios anteriores mostraron una respuesta rápida a las noticias en la apertura del mercado (Boudoukh et al. (2019); Greene y Watts (1996); y otros). Se entrenó y utilizó un modelo moderno de lenguaje natural basado en BERT en la base de datos de noticias financieras de Thomson Reuters. Esto permitió analizar la reacción del mercado al sentimiento de las noticias.
Hay tres contribuciones principales de este estudio.
- Los autores documentaron el impacto del sentimiento de las noticias de la noche a la mañana en el precio de apertura del mercado e informan de una fijación errónea de precios que conduce a una reversión predecible de la rentabilidad. La reacción al sentimiento de las noticias es aparentemente asimétrica, dependiendo de la dirección del retorno del día anterior en relación con el sentimiento de las noticias. En ausencia de noticias nocturnas específicas de la empresa, es muy difícil predecir los rendimientos del día siguiente.
- La reinvestigación del efecto de atención informado por Barber y Odean (2008) y Berkman et al. (2012). Esos estudios afirman que una mayor atención de los inversores (indicada por grandes rendimientos absolutos del día anterior) conduce a precios elevados en la apertura del mercado, seguidos de una reversión durante el día de negociación. Se detectó este efecto incondicional sobre los comunicados de prensa, pero en ausencia de noticias nocturnas, es mucho menos significativo que el efecto del sentimiento de las noticias sobre los precios de los activos.
- Se presentó la estrategia comercial simple que explota la reversión nocturna al tomar una posición larga (corta) en la subasta de apertura de acciones que experimentaron rendimientos idiosincrásicos excepcionalmente negativos (positivos) en el día de negociación anterior solo si observamos noticias nocturnas.
En particular, los autores documentan una reversión de rendimiento predecible de los rendimientos del día anterior en días con noticias nocturnas relevantes para la empresa. Cuando no hay noticias de la noche a la mañana, la previsibilidad es sólo marginal. Este patrón resulta de las respuestas asimétricas de los inversionistas al sentimiento de las noticias.
Sentimiento de noticias y rentabilidad de las acciones: modelo BERT ML
Enlace: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3971880
La idea principal del artículo es investigar el impacto de las noticias financieras en los rendimientos de las acciones e introducir un modelo no paramétrico. Este modelo se utiliza para generar una señal de sentimiento, que posteriormente se utiliza como predictor de pronósticos de rendimiento de acciones de acciones individuales a corto plazo. Los autores toman el modelo BERT de Google y lo entrenan secuencialmente con las noticias financieras de Thomson Reuters (período de tiempo de 1996 a 2020). Se realizó una investigación de la capacidad de un modelo de lenguaje basado en BERT para generar una puntuación de sentimiento a partir de artículos de noticias financieras para predecir rendimientos de acciones a corto plazo. El modelo BERT se modificó para los propósitos específicos de este estudio y se encontró que este modelo es capaz de extraer señales sentimentales de las noticias financieras. Esta señal tiene una correlación positiva con la rentabilidad de los activos. Se encontró que las noticias tienden a inducir rendimientos anormales más fuertes en el día t que las noticias recientes, mientras que la información de las noticias financieras se incorpora a los precios de las acciones dentro de un día. La categorización de artículos de noticias en temas puede proporcionar información, que se puede utilizar como características adicionales y esto puede ayudar a hacer modelos más precisos y mejorar la capacidad del modelo para predecir futuros rendimientos de activos. Si solo se consideran los datos del tema «Previsión del analista», se producen las previsiones más precisas de los rendimientos futuros de los activos. Los autores de este artículo se concentran en las empresas S&P 500 con grandes capitalizaciones de mercado. Se descubrió que las noticias financieras se incorporan rápidamente a los precios de los activos. A pesar del tamaño más pequeño del modelo creado por los autores, en comparación con FinBERT (Araci, 2019) y el modelo BERT de tamaño completo, muestra un desempeño superior fuera de la muestra (Tabla 9). Los autores creen que la alta calidad del modelo está condicionada por la combinación del entrenamiento previo específico del dominio y su clasificador de redes neuronales profundas entrenado con pérdida de entropía cruzada simétrica en un gran conjunto de datos de noticias financieras anotadas.
Referencias:
[2] Rogers, A., Kovaleva, O. y Rumshisky, A. (2021). Introducción a BERTology: lo que sabemos sobre cómo funciona BERT. Transacciones de la Asociación de Lingüística Computacional 8 , 842-866.
[3] https://towardsdatascience.com/transformer-in-cv-bbdb58bf335e
[4] Liddy, ED (2001). Procesamiento natural del lenguaje.
[5] Devlin, J., Chang, MW y Toutanova, K. (2018). Bert: Pre-entrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje. preimpresión de arXiv arXiv:1810.04805
[6] https://huggingface.co/blog/bert-101
[7] https://www.turing.com/kb/how-bert-nlp-optimization-model-works – what-is-bert?
[8] https://www.geeksforgeeks.org/understanding-bert-nlp/
[9] Jain, A., Ruohe, A., Grönroos, SA y Kurimo, M. (2020). Modelado del idioma finlandés con modelos de transformadores profundos. preimpresión de arXiv arXiv:2003.11562.
[11] https://devopedia.org/bert-language-model
[12] http://jalammar.github.io/illustrated-bert/
[13] https://d35fo82fjcw0y8.cloudfront.net/2019/05/27153113/what-is-natural-language-processing.jpg
[14] https://machinelearningmastery.com/wp-content/uploads/2021/08/attention_research_1.png
Referencias relacionadas:
ELMo
https://allenai.org/allennlp/software/elmo
Conceptos básicos del modelo BERT
https://en.wikipedia.org/wiki/BERT_(language_model)
https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
https://huggingface.co/blog/bert-101
Autor:
Lukas Zelieska, analista cuantitativo