
El objetivo de Quantinsti es formar a su alumnos en el trading algorítmico. Pertenece a iRageCapital Advisory, empresa conocida por sus servicios relacionados con la creación de mesas de trading algorítmico.
Redes Neuronales en Python
Esta tercera parte de Redes Neuronales en Python incluye los siguientes tópicos:
- Red Neuronal en el Trading
- Estrategia de Redes Neuronales en Python
- Paso 1: Importar Bibliotecas
- Paso 2: Obtener datos de Yahoo Finance
- Paso 3: Preparar el conjunto de datos
- Paso 4: Definiendo las características de entrada del conjunto de datos
- Paso 5: Estandarización del conjunto de datos (preprocesamiento de datos)
- Paso 6: Construyendo el modelo de red neuronal artificial
- Paso 7: Configurando los parámetros de predicción
- Paso 8: Cálculo de los rendimientos de la estrategia y determinación de las posiciones de trading
- Conclusión
Red Neuronal en el Trading
Las redes neuronales ayudan a desarrollar estrategias basadas en la estrategia general de inversión. Ya sea de alto riesgo y enfocada en el crecimiento (operaciones a corto plazo) o una estrategia conservadora para inversiones a largo plazo, depende del tipo de estrategia de trading.
Por ejemplo, si deseas encontrar algunas acciones con un rendimiento de crecimiento particular o una tendencia alcista en el precio durante un período de un año, la red neuronal puede identificar esas acciones para tu portafolio, facilitando tu trabajo.
Estrategia de Redes Neuronales en Python
A continuación, veamos la representación estratégica con redes neuronales en Python.
Paso 1: Importar Bibliotecas
Comenzaremos importando algunas bibliotecas. Las otras se importarán a medida que se necesiten en el programa. Por ahora, importamos las bibliotecas que nos ayudarán a importar y preparar el conjunto de datos para entrenar y probar el modelo.
«`python
import numpy as np
import pandas as pd
import talib
«`
`Numpy` es un paquete fundamental para la computación científica. Lo utilizaremos para realizar cálculos sobre nuestro conjunto de datos. La biblioteca se importa usando el alias `np`.
`Pandas` nos ayudará con el poderoso objeto de dataframe, que se usará durante todo el código para construir la red neuronal artificial en Python.
`Ta-lib` es una biblioteca de análisis técnico que se usará para calcular el RSI y Williams %R, que serán características utilizadas para entrenar nuestra red neuronal.
Paso 2: Obtener datos de Yahoo Finance
«`python
import random
random.seed(42)
«`
`Random` se usa para inicializar la semilla a un número fijo para que cada vez que ejecutemos el código, comencemos con la misma semilla.
«`python
price_AAPL = yf.download(‘AAPL’, start=’2017-11-06′, end=’2023-01-03′, auto_adjust=True)
«`
Tomamos los datos de Apple del 6 de noviembre de 2017 al 3 de enero de 2023.
Paso 3: Preparar el conjunto de datos
Construiremos nuestras características de entrada utilizando solo los valores OHLC. Este conjunto de datos nos ayudará a especificar las características para entrenar nuestra red neuronal en el siguiente paso.
price_AAPL[‘H-L’] = price_AAPL[‘High’] – price_AAPL[‘Low’]
price_AAPL[‘O-C’] = price_AAPL[‘Close’] – price_AAPL[‘Open’]
price_AAPL[‘3day MA’] = price_AAPL[‘Close’].shift(1).rolling(window=3).mean()
price_AAPL[’10day MA’] = price_AAPL[‘Close’].shift(1).rolling(window=10).mean()
price_AAPL[’30day MA’] = price_AAPL[‘Close’].shift(1).rolling(window=30).mean()
price_AAPL[‘Std_dev’] = price_AAPL[‘Close’].rolling(5).std()
price_AAPL[‘RSI’] = talib.RSI(price_AAPL[‘Close’].values, timeperiod=9)
price_AAPL[‘Williams %R’] = talib.WILLR(price_AAPL[‘High’].values, price_AAPL[‘Low’].values, price_AAPL[‘Close’].values, 7)
Paso 4: Definiendo las características de entrada del conjunto de datos
Luego preparamos las diversas características de entrada que utilizará la red neuronal artificial para realizar las predicciones. Definimos las siguientes características de entrada:
– Precio máximo menos precio mínimo
– Precio de cierre menos precio de apertura
– Media móvil de tres días
– Media móvil de diez días
– Media móvil de 30 días
– Desviación estándar de un período de 5 días
– Índice de Fuerza Relativa (RSI)
– Williams %R
Después, definimos el valor de salida como el incremento del precio, que es una variable binaria que almacena 1 cuando el precio de cierre de mañana es mayor que el de hoy.
«`python
price_AAPL[‘Price_Rise’] = np.where(price_AAPL[‘Close’].shift(-1) > price_AAPL[‘Close’], 1, 0)
«`
A continuación, eliminamos todas las filas que contienen valores NaN usando la función `dropna()`.
«`python
price_AAPL = price_AAPL.dropna()
«`
Luego creamos dos dataframes para almacenar las variables de entrada y salida. El dataframe ‘X’ almacena las características de entrada. Las columnas comienzan desde la quinta columna del conjunto de datos y continúan hasta la penúltima columna. La última columna se almacena en el dataframe ‘y’, que es el valor de predicción (incremento del precio).
«`python
X = price_AAPL.iloc[:, 4:-1]
y = price_AAPL.iloc[:, -1]
«`
En esta parte del código, dividiremos nuestras variables de entrada y salida para crear los conjuntos de datos de prueba y entrenamiento. Esto se hace creando una variable llamada `split`, que se define como el valor entero del 80% de la longitud del conjunto de datos.
Luego, dividimos las variables `X` y `y` en cuatro dataframes separados: `X_train`, `X_test`, `y_train` y `y_test`. Esta es una parte esencial de cualquier algoritmo de aprendizaje automático, ya que los datos de entrenamiento se utilizan para que el modelo ajuste los pesos.
«`python
Dividiendo el conjunto de datos
split = int(len(price_AAPL) * 0.8)
X_train, X_test, y_train, y_test = X[:split], X[split:], y[:split], y[split:]
«`
El conjunto de datos de prueba se utiliza para ver cómo se desempeñará el modelo con nuevos datos. Además, se compara el valor real con el valor predicho para evaluar la eficiencia del modelo.
Paso 5: Estandarización del conjunto de datos (preprocesamiento de datos)
Otro paso importante en el preprocesamiento es la estandarización del conjunto de datos, lo que hace que la media de todas las características de entrada sea igual a cero y la varianza sea 1. Esto evita que el modelo le dé mayor peso a las características con valores más grandes.
Este paso se implementa importando el método `StandardScaler` de la librería `sklearn.preprocessing`.
«`python
Escalado de características
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
«`
Paso 6: Construyendo el modelo de red neuronal artificial
Luego, usamos la función `fit_transform` para aplicar estos cambios a los conjuntos `X_train` y `X_test`. Las variables `y_train` y `y_test` contienen valores binarios, por lo que no necesitan ser estandarizadas. Una vez que los conjuntos de datos están listos, podemos proceder a construir la red neuronal artificial utilizando la librería Keras.
Importamos las funciones necesarias para construir la red neuronal. Usamos el método `Sequential` de `keras.models` para construir las capas de la red.
«`python
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
«`
Instanciamos la función `Sequential()` en la variable `classifier`, que se utilizará para construir las capas de la red neuronal.
«`python
classifier = Sequential()
«`
Para agregar capas a nuestro clasificador, utilizamos la función `add()`. El argumento de la función `add` es la función `Dense()`, que a su vez tiene los siguientes argumentos:
– Units (Unidades): Esto define el número de nodos o neuronas en esa capa en particular. Hemos establecido este valor en 128, lo que significa que habrá 128 neuronas en nuestra capa oculta.
– Kernel_initializer: Esto define los valores iniciales para los pesos de las diferentes neuronas en la capa oculta. Lo hemos definido como ‘uniform’, lo que significa que los pesos se inicializarán con valores de una distribución uniforme.
– Activation (Activación): Esta es la función de activación para las neuronas en la capa oculta. Aquí definimos la función como la función lineal rectificada o ‘relu’.
– Input_dim: Esto define el número de entradas a la capa oculta; hemos definido este valor igual al número de columnas de nuestro dataframe de características de entrada. Este argumento no será necesario en las capas posteriores, ya que el modelo sabrá cuántas salidas produjo la capa anterior.
«`python
classifier.add(Dense(units=128, kernel_initializer=’uniform’, activation=’relu’, input_dim=X.shape[1]))
«`
Luego, agregamos una segunda capa, con 128 neuronas, un inicializador de kernel uniforme y ‘relu’ como su función de activación. Solo estamos construyendo dos capas ocultas en esta red neuronal.
«`python
classifier.add(Dense(units=128, kernel_initializer=’uniform’, activation=’relu’))
«`
La siguiente capa que construiremos será la capa de salida, de la cual requerimos una única salida. Por lo tanto, el valor de `units` será 1, y la función de activación elegida es la función Sigmoid, ya que queremos que la predicción sea una probabilidad de que el mercado suba.
«`python
classifier.add(Dense(units=1, kernel_initializer=’uniform’, activation=’sigmoid’))
«`
Finalmente, compilamos el clasificador pasando los siguientes argumentos:
– Optimizer (Optimizador): El optimizador elegido es ‘adam’, que es una extensión del descenso de gradiente estocástico.
– Loss (Pérdida): Esto define la función de pérdida a optimizar durante el entrenamiento. Definimos esta pérdida como el error cuadrático medio.
– Metrics (Métricas): Esto define la lista de métricas que serán evaluadas por el modelo durante la fase de prueba y entrenamiento. Hemos elegido la precisión como nuestra métrica de evaluación.
«`python
classifier.compile(optimizer=’adam’, loss=’mean_squared_error’, metrics=[‘accuracy’])
«`
Ahora necesitamos ajustar la red neuronal que hemos creado a nuestros conjuntos de datos de entrenamiento. Esto se hace pasando `X_train`, `y_train`, el tamaño de lote y el número de épocas en la función `fit()`.
El tamaño de lote se refiere al número de puntos de datos que el modelo usa para calcular el error antes de retropropagar los errores y hacer modificaciones a los pesos. El número de épocas representa cuántas veces se realizará el entrenamiento del modelo en el conjunto de datos de entrenamiento.
«`python
classifier.fit(X_train, y_train, batch_size=10, epochs=100)
«`
Paso 7: Configurando los parámetros de predicción
Con esto, nuestra red neuronal artificial en Python ha sido compilada y está lista para hacer predicciones.
Ahora que la red neuronal ha sido compilada, podemos usar el método `predict()` para realizar la predicción. Pasamos `X_test` como argumento y almacenamos el resultado en una variable llamada `y_pred`. Luego, convertimos `y_pred` para almacenar valores binarios utilizando la condición `y_pred > 0.5`. Ahora, la variable `y_pred` almacena valores `True` o `False` dependiendo de si el valor predicho fue mayor o menor a 0.5.
«`python
Prediciendo el movimiento del stock
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
«`
A continuación, creamos una nueva columna en el dataframe con el encabezado de columna ‘y_pred’ y almacenamos valores `NaN` en dicha columna. Luego, almacenamos los valores de `y_pred` en esta nueva columna, comenzando desde las filas del conjunto de datos de prueba.
Esto se hace dividiendo el dataframe utilizando el método `iloc`, como se muestra en el código anterior. Luego, eliminamos todos los valores `NaN` del conjunto de datos y los almacenamos en un nuevo dataframe llamado `trade_price_AAPL`.
«`python
price_AAPL[‘y_pred’] = np.NaN
price_AAPL.iloc[(len(price_AAPL) – len(y_pred)):, -1:] = y_pred
trade_price_AAPL = price_AAPL.dropna()
«`
Paso 8: Cálculo de los rendimientos de la estrategia y determinación de las posiciones de trading
Ahora que tenemos los valores predichos del movimiento de las acciones, podemos calcular los rendimientos de la estrategia. Tomaremos una posición larga cuando el valor predicho de y sea verdadero y tomaremos una posición corta cuando la señal predicha sea falsa.
Primero calculamos los rendimientos que la estrategia ganará si se toma una posición larga al final del día de hoy y se liquida al final del día siguiente. Comenzamos creando una nueva columna llamada «Rendimientos de Mañana» en el dataframe *trade_price_AAPL* y almacenamos en ella un valor de 0.
Usamos notación decimal para indicar que se almacenarán valores de punto flotante en esta nueva columna. A continuación, almacenamos en ella los rendimientos logarítmicos de hoy, es decir, el logaritmo del precio de cierre de hoy dividido por el precio de cierre de ayer. Luego, desplazamos estos valores hacia arriba por un elemento para que los rendimientos de mañana se almacenen contra los precios de hoy.
«`python
# Cálculo de los rendimientos de la estrategia
trade_price_AAPL[‘Rendimientos de Mañana’] = 0.
trade_price_AAPL[‘Rendimientos de Mañana’] = np.log(trade_price_AAPL[‘Close’]/trade_price_AAPL[‘Close’].shift(1))
trade_price_AAPL[‘Rendimientos de Mañana’] = trade_price_AAPL[‘Rendimientos de Mañana’].shift(-1)
«`
A continuación, calcularemos los rendimientos de la estrategia. Creamos una nueva columna bajo el encabezado «Rendimientos de Estrategia» e inicializamos con un valor de 0 para indicar el almacenamiento de valores de punto flotante.
Usando la función `np.where()`, almacenamos el valor en la columna «Rendimientos de Mañana» si el valor en la columna «y_pred» es verdadero (una posición larga); de lo contrario, almacenamos el valor negativo de la columna «Rendimientos de Mañana» (una posición corta) en la columna «Rendimientos de Estrategia».
«`python
trade_price_AAPL[‘Rendimientos de Estrategia’] = 0.
trade_price_AAPL[‘Rendimientos de Estrategia’] = np.where(trade_price_AAPL[‘y_pred’] == True, trade_price_AAPL[‘Rendimientos de Mañana’], – trade_price_AAPL[‘Rendimientos de Mañana’])
«`
Ahora calculamos los rendimientos acumulados tanto para el mercado como para la estrategia. Estos valores se calculan usando la función `cumsum()`. Usaremos la suma acumulativa para trazar el gráfico de los rendimientos del mercado y la estrategia en el último paso.
«`python
trade_price_AAPL[‘Rendimientos Acumulados del Mercado’] = np.cumsum(trade_price_AAPL[‘Rendimientos de Mañana’])
trade_price_AAPL[‘Rendimientos Acumulados de la Estrategia’] = np.cumsum(trade_price_AAPL[‘Rendimientos de Estrategia’])
«`
A continuación, trazaremos los rendimientos del mercado y los rendimientos de nuestra estrategia para visualizar cómo se está desempeñando nuestra estrategia frente al mercado. Para esto, importaremos `matplotlib.pyplot`.
Luego, usamos la función `plot()` para trazar los gráficos de los Rendimientos del Mercado y Rendimientos de la Estrategia usando los valores acumulados almacenados en el dataframe `trade_dataset`. Creamos la leyenda y mostramos el gráfico usando las funciones `legend()` y `show()` respectivamente.
«`python
# Graficar los rendimientos
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.plot(trade_price_AAPL[‘Rendimientos Acumulados del Mercado’], color=’r’, label=’Rendimientos del Mercado’)
plt.plot(trade_price_AAPL[‘Rendimientos Acumulados de la Estrategia’], color=’g’, label=’Rendimientos de la Estrategia’)
plt.title(‘Rendimientos del Mercado y de la Estrategia’, color=’purple’, size=15)
# Etiquetas de los ejes
plt.xlabel(‘Fechas’, {‘color’: ‘orange’, ‘fontsize’:15})
plt.ylabel(‘Rendimientos(%)’, {‘color’: ‘orange’, ‘fontsize’:15})
plt.legend()
plt.show()
«`
El gráfico mostrado es el resultado del código. La línea verde representa los rendimientos generados usando la estrategia y la línea roja representa los rendimientos del mercado.
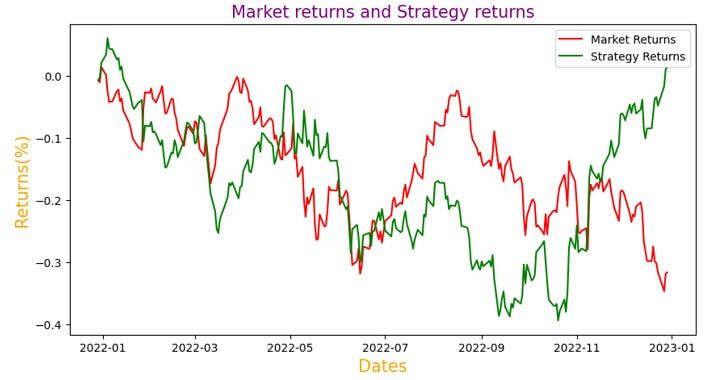
Puedes observar en la salida anterior que los rendimientos de la estrategia alcanzaron su punto máximo en enero de 2023 después de fluctuar (hacia arriba y hacia abajo) durante los otros períodos de tiempo.
Los rendimientos de la estrategia superan ocasionalmente los rendimientos del mercado.
De manera similar, puedes modificar los parámetros de la estrategia según tu comprensión del mercado y expectativas.
Conclusión
Creemos que ahora puedes construir tu propia Red Neuronal Artificial en Python y comenzar a operar utilizando la potencia e inteligencia de tus máquinas.
Además de las Redes Neuronales, existen muchos otros modelos de aprendizaje automático que se pueden utilizar para operar. La Red Neuronal Artificial o cualquier otro modelo de Deep Learning será más efectivo cuando tengas más de 100,000 puntos de datos para entrenar el modelo.
Este modelo se desarrolló con precios diarios para hacerte entender cómo construir el modelo. Se recomienda usar datos por minuto o por tick para entrenar el modelo, lo que te dará suficientes datos para un entrenamiento efectivo.
Puedes inscribirte en el curso de redes neuronales de Quantra, donde puedes usar técnicas avanzadas de redes neuronales y los últimos modelos de investigación, como LSTM y RNN, para predecir mercados y encontrar oportunidades de trading. Keras, la biblioteca de Python relevante, es utilizada.
Bibliografía