
- El objetivo de la optimización de un sistema de trading no debe ser nunca encontrar una curva de resultados espectacular, sino un sistema robusto y rentable. Buscar lo primero es el error más frecuente entre los novatos del trading automático. La rentabilidad se encuentra al conseguir lo segundo. Veamos cómo lograrlo.
- Artículo publicado en Hispatrading 34.
En este artículo se mostrará cómo, para encontrar ineficiencias explotables que generen ventaja frente al mercado, podemos emplear diferentes aproximaciones. Una de una de ellas es el uso de algoritmos inteligentes y el análisis de clusters robustos k-means.
Encontrando ineficiencias explotables
Para que un sistema de trading sea rentable, primero tenemos que encontrar una ineficiencia explotable. Para esto, podemos utilizar diferentes métodos. Por ejemplo, partiendo de una teoría económica podríamos aplicar, de forma progresiva, distintas reglas que detecten que el suceso se está dando. Esta aproximación deductiva no es mi favorita, ya que supone partir de una teoría económica válida o al menos aproximadamente válida… y esto no siempre es fácil.
Pero podemos resolver el problema desde otro ángulo: mediante técnicas de minería de datos que extraigan directamente la ineficiencia de los producidos por el mercado (principalmente el precio e indicadores derivados de este). Si planteamos una ineficiencia (por ejemplo, la divergencia entre el valor de un activo y su precio) y aplicamos un análisis estructural a nivel de información de estos datos de mercado, el resultado será una serie de condiciones que actuarán como patrón detector de la misma ineficiencia.
Después ejecutaremos la operación y mediante otras técnicas de inteligencia artificial podremos gestionarla, delimitando, por ejemplo, las zonas de toma de beneficio o seleccionando el apalancamiento adecuado en función de nuestros objetivos de rentabilidad y riesgo.
Pero en todo este proceso el núcleo fundamental se encuentra en validar la ineficiencia. Debido a que utilizamos técnicas de optimización muy potentes, el peligro de sobreoptimizar el sistema es elevado. La sobreoptimización es el peor enemigo del trader de sistemas, ya que nadie operaría en real con un sistema que en backtest no fuera rentable. No obstante, si el sistema está sobreoptimizado y en backtest parece rentable, sí lo haremos y perderemos dinero.
Por lo tanto, es fundamental poder analizar cuándo un sistema es robusto y no está sobreoptimizado. Veamos ahora cómo hacerlo.
Diseñando sistemas robustos
Cuando empezamos a diseñar un sistema, es importante partir de un método que ya de por sí dé bastantes garantías de no sobreoptimizar y, al mismo tiempo, sea lo suficientemente potente para encontrar la ineficiencia. A este respecto, empleo, como ya he comentado, mi propio método basado en algoritmos de inteligencia artificial y minería de datos. Pero después, en un segundo paso, debemos analizar los resultados para determinar la robustez del sistema. Es precisamente en este momento donde empleo el método de optimización mediante clusters k-means.
A la hora de seleccionar una buena optimización, solemos fijarnos en diferentes criterios numéricos como, por ejemplo, el SQN. Sin embargo, nos interesa evitar el caso en el que seleccionemos una estrategia que quede muy bien puntuada pero en cuyo vecindario (optimizaciones calculadas con ligeras variaciones de los parámetros) abunden las optimizaciones mediocres o, directamente, malas. Es preferible, por tanto, seleccionar una optimización no tan buena pero cuyo vecindario mantenga puntuaciones parecidas.
El procedimiento conocido como clustering o análisis de conglomerados nos permite realizar este análisis, al agrupar optimizaciones similares y poder ver sus puntuaciones en conjunto. Este clustering se realiza mediante el algoritmo k-means, de probada eficiencia, fiabilidad y robustez. Optimizando mediante clusters k-means
La técnica es sencilla de aplicar y los resultados son inmejorables. ¿En qué consiste? Básicamente se trata de encontrar, en el espacio de optimizaciones, una zona robusta. Cuando nuestro sistema consta de solo dos parámetros (como pueda ser al optimizar los objetivos de stop y beneficio) es muy sencillo y se puede hacer incluso visualmente. Pero ¿qué sucede a partir de tres parámetros o más? Ya tenemos un espacio n-dimensional que no puede ser visualizado y ahí es donde podemos equivocarnos. Sin embargo, k-means es capaz de encontrar agrupaciones robustas en n-dimensiones y ofrecernos el conjunto de parámetros óptimo en cuanto a robustez del sistema se refiere.
¿Cómo trabaja?
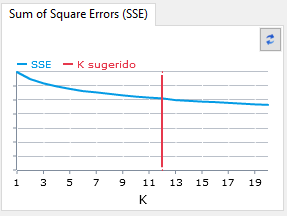
Lo primero que hace el algoritmo es determinar en cuántas particiones va a dividir el espacio: serán las k particiones que dan nombre al algoritmo. Podríamos probar con distintos números 2, 3, 5, 7, etc. Pero hemos implementado un algoritmo que, basado en el error estimado, calcula el número k de particiones óptimo para cada espacio de optimizaciones. Con esto, el algoritmo lanza la búsqueda de centroides en las particiones y nos entrega los resultados óptimos que serían los centroides de cada cluster.
Análisis de una optimización
Utilizando nuestra plataforma Alphadvisor podemos analizar una optimización de un sistema intradiario para el EURUSD. El sistema está diseñado mediante mi método inteligente de minería de datos e incluye un sistema de red neuronal para filtrar entradas. Sin embargo hemos dejado los objetivos de stoploss y takeprofit para optimizar libremente mediante un algoritmo genético orientado mediante una función objetivo propia.
En la figura vemos los distintos apartados de exploración de una optimización de k-means. Vamos a describirlos uno a uno.
Con el número (1) tenemos el selector k de número de clusters. Con esto delimitamos las particiones del sistema. Justo debajo está la gráfica del algoritmo que optimiza el número K mediante reducción de errores.
Con el número (2) podemos ir navegando entre los diferentes clusters generados. Esto modificará toda la información mostrada en pantalla. Vemos los dos parámetros (en azul) que se han optimizado: el stoploss y el takeprofit. A continuación se muestran los diferentes valores de rendimiento obtenidos por el cluster (beneficios, número de operaciones, factor de beneficio, esperanza, disminución, valor de la función objetivo optimizada y número de muestras del cluster).
En el número (3) el gráfico de araña muestra para el cluster la distribución de los valores de rendimiento descritos anteriormente.
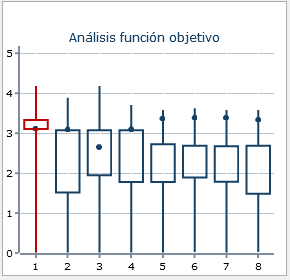
En el número (4) cada vela representa uno de los clusters y el punto nos dice dónde se encuentra el centroide respecto al cluster.
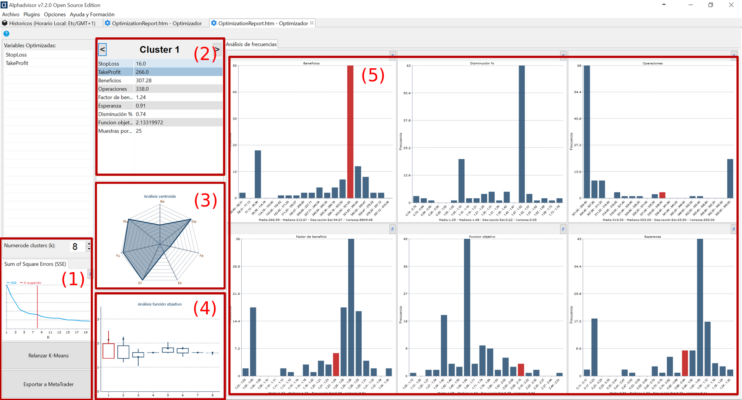
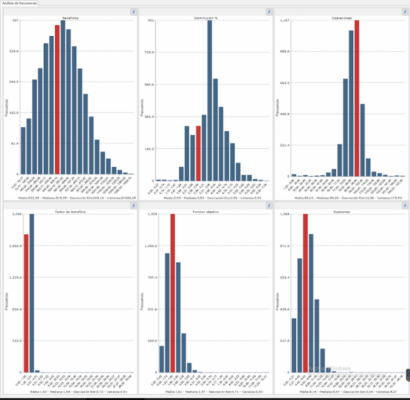
Finalmente, en el número (5) vemos las diferentes distribuciones de todo el espacio de optimización para los valores de rendimiento. En cada uno de ellos mostramos en rojo donde se sitúa el cluster seleccionado actualmente.
Mediante este optimizador podemos analizar el espacio de optimizaciones de nuestro sistema y generar los diferentes clusters k-means.
El centroide en cada uno de ellos es un conjunto de parámetros que hace robusto al sistema. Ya solo queda seleccionar el mejor o incluso los mejores para introducirlos como parámetros de nuestro sistema de trading y empezar a operar con altas garantías en cuanto a la solidez de nuestro sistema.