![]()
Al leer el título de este artículo, la primera pregunta que puede surgir es por qué alguien querría replicar una cartera de factores de riesgo. Sin embargo, hay muchas razones por las que es beneficioso replicar una cartera de factores.
Por ejemplo, dado que los ETF se desarrollaron en la década de 1990, solo se dispone de ventanas de tiempo históricas muy limitadas para analizar su rendimiento en condiciones de mercado extremas. Además, muchas estrategias se basan en ETF, por lo que sus historiales suelen tener solo 20 años, a menudo mucho más cortos. Tener la capacidad de replicar cualquier cartera de factores con un historial más largo podría brindarnos innumerables datos valiosos.
Otra razón para replicar podría ser un interés en la cartera de otra persona. ¿Qué factores impulsan los rendimientos de mi competidor? Por otro lado, es posible que también desee averiguar a qué factores es más sensible su propia cartera. Cualquiera que sea el caso para usted, tener un historial de datos más extenso siempre es beneficioso.
Por lo tanto, examinamos 16 factores y los usamos para replicar varias carteras en los siguientes pasos:
- En el primer paso, sincronizamos las fechas del factor y la cartera para permitir más cálculos.
- En segundo lugar, utilizamos el análisis de regresión multifactorial en combinación con el criterio de información de Akaike (AIC) para encontrar los factores explicativos de una cartera y sus ponderaciones. Aplicamos el procedimiento al historial disponible de la cartera de insumos.
- En tercer lugar, verificamos nuestra calidad de ajuste visualizando las curvas de equidad de las carteras original y de factores para el historial disponible de una cartera de entrada.
- Por último, ampliamos el historial de una cartera a 100 años mediante el modelado de una cartera de entrada a través de factores con un rico historial de datos, creado en base a la metodología única de Quantpedia.
Ahora profundizaremos en la metodología en las siguientes secciones.
100 años de datos diarios de Factores
En primer lugar, tuvimos que elegir cuidadosamente nuestro universo de factores, es decir, cuál será nuestro bloque de construcción para modelar carteras y estrategias. En esta elección tuvimos que tener en cuenta ambos:
- Tener suficientes factores de mercado no correlacionados y representativos para varias clases de activos
- Disponibilidad de datos a largo plazo para tales factores subyacentes
Sin embargo, encontrar datos de factores con un historial de 100 años es casi imposible. Por lo tanto, tuvimos que ser creativos y producir nuestra propia serie de datos. Con la excepción de algunos factores, combinamos varias fuentes de datos para obtener datos históricos desde 1926. A continuación, enumeramos los factores y una breve descripción de la metodología para obtener los datos.
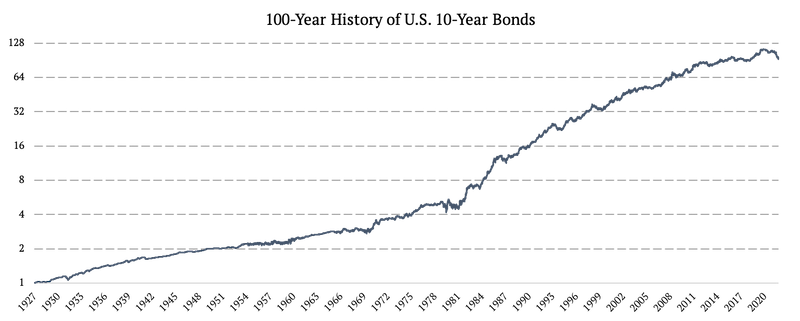
Bonos estadounidenses a 10 años (US10Y)
Describimos el proceso de creación de un historial de 100 años de bonos estadounidenses a 10 años en detalle en nuestro manual de datos: Ampliación de los datos históricos diarios de bonos a 100 años. Para obtener el historial de 100 años, combinamos tres fuentes de datos:
1926 – 1962: Rendimiento mensual de los bonos estadounidenses a 10 años
1962 – 2002: Rendimiento diario de los bonos estadounidenses a 10 años
2002 – 2022: IEF ETF (ETF de bonos del Tesoro iShares de 7 a 10 años)
De 1926 a 1962 se trabajó con rendimientos mensuales y de 1962 a 2002 con rendimientos diarios. En primer lugar, transformamos los rendimientos de los bonos en rendimientos totales. Una vez calculadas las rentabilidades, el segundo reto fue transformar las rentabilidades mensuales de 1926 a 1962 en diarias.
Logramos eso extrapolando la volatilidad diaria de las letras del Tesoro de EE. UU. a 3 meses, nuestro método único que llamamos «extrapolación de proxy de volatilidad». En términos simples, copiamos la volatilidad diaria de las letras del Tesoro de 3 meses y la conectamos entre dos puntos de datos mensuales de los bonos del Tesoro de EE. UU. a 10 años.
Como se mencionó anteriormente, este es solo un breve resumen de la metodología. Si está interesado en los detalles específicos de cualquiera de los pasos, consulte Ampliación de los datos históricos diarios de bonos a 100 años .
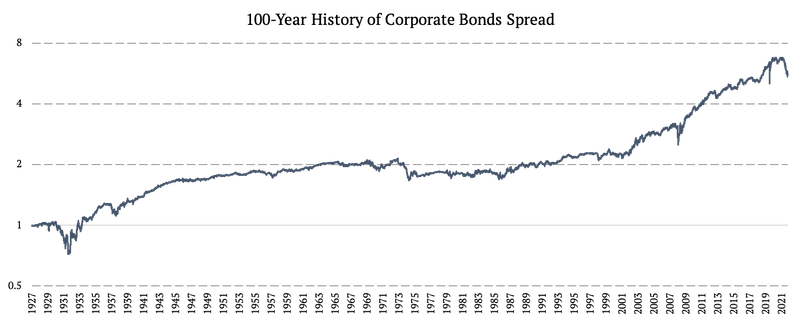
Diferencial de Bonos Corporativos (BAA CORP)
Para obtener un historial de 100 años de bonos corporativos, combinamos las siguientes fuentes de datos:
1926 – 1985: Rendimiento mensual de los bonos corporativos de Baa ( https://fred.stlouisfed.org/series/BAA )
1986 – 2002: Rendimiento diario de bonos corporativos de Baa ( https://fred.stlouisfed.org/series/DBAA )
2002 – 2022: LQD ETF (iShares iBoxx $ Investment Grade Corporate Bond ETF)
De manera similar a los bonos estadounidenses a 10 años, aplicamos la extrapolación de proxy de volatilidad diaria a los rendimientos mensuales para la primera fuente de datos. Solo que esta vez, utilizamos los rendimientos del mercado de acciones ajustados beta como fuente de volatilidad. La beta se calculó de modo que la volatilidad del mercado de acciones coincidiera con la volatilidad de los bonos.
Durante los dos primeros períodos, tuvimos que transformar nuevamente los rendimientos de los bonos en rendimientos totales, de la misma manera que ocurrió con los rendimientos del Tesoro de EE. UU. descritos anteriormente. Para comprender mejor toda nuestra metodología de datos, le recomendamos que lea Extender los datos históricos diarios de bonos a 100 años .
Por último, utilizamos los datos de los bonos corporativos en forma de diferencial frente a los bonos del Tesoro de EE. UU. De esta manera, podemos aislar el efecto del diferencial de crédito e incluirlo por separado, además de un efecto de «curva» representado por los bonos del Tesoro de EE. UU.
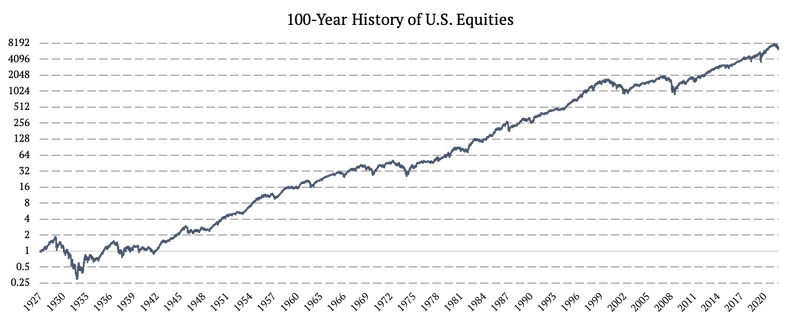
Acciones de EE. UU. (RENTA VARIABLE DE EE. UU.)
La construcción del factor de acciones de EE. UU. fue bastante sencilla. Simplemente combinamos el factor de mercado de Fama y Francia (1926 – 1993) de la biblioteca de datos de Fama y Francia y los rendimientos diarios del ETF de SPY (SPDR S&P 500 ETF Trust) (1993 – 2022).
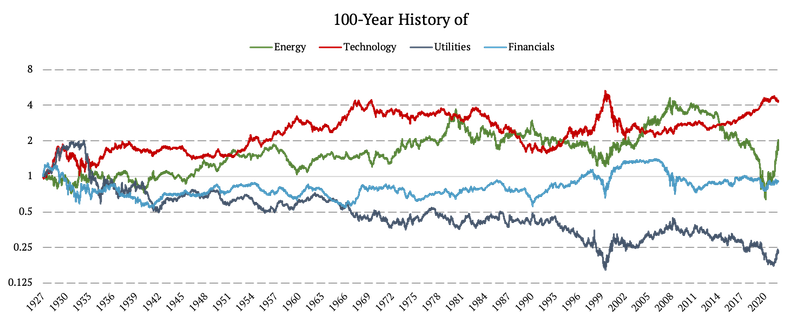
Diferenciales de los sectores de renta variable de EE. UU. (energía, tecnología, servicios públicos, finanzas)
Los datos de los factores de mercado se obtuvieron de la biblioteca de datos de Fama & French, específicamente de las 12 carteras de la industria [Diario]. Nosotros usamos:
- la difusión de la industria energética frente al mercado como factor energético
- la difusión de la industria de Equipos de Negocios contra el mercado como el factor de Tecnología
- la difusión de la industria de Utilities contra el mercado como factor de Utilities, y
- la propagación de la industria del dinero frente al mercado como factor financiero.
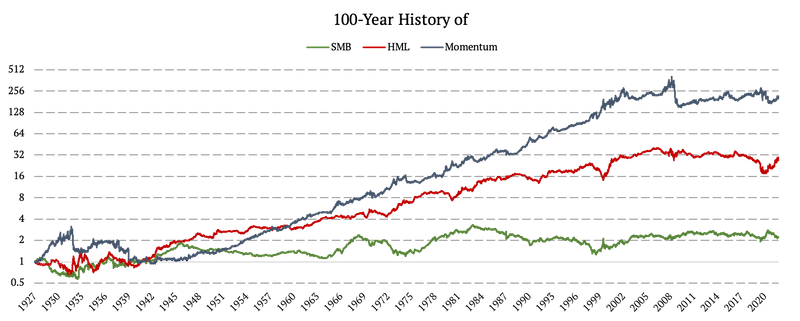
Fama y factores franceses (SMB, HML, Momentum)
De manera similar, obtuvimos datos para los factores Small-Minus-Big (SMB), High-Minus-Low (HML) y Momentum de la biblioteca de datos de Fama y French. Sin embargo, no se calcularon diferenciales para estos factores, porque ya tienen la forma de un diferencial largo-corto. Los factores están disponibles desde 1926 hasta hoy.
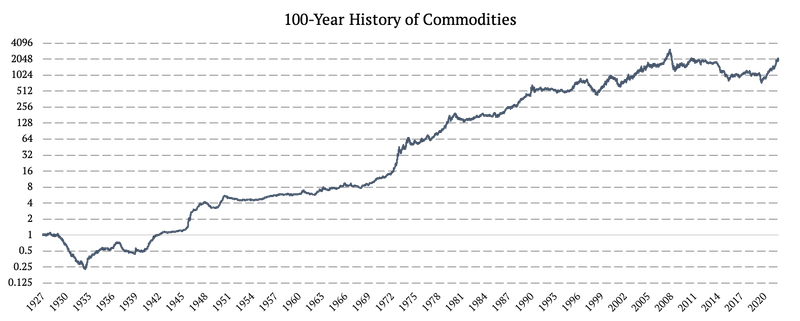
Materias primas
El proceso de obtención de un historial de 100 años de datos de materias primas se describe detalladamente en el manual de datos de Quantpedia: Ampliación de los datos históricos diarios de materias primas a 100 años. Utilizamos tres fuentes de datos:
1926 – 1979: IPP mensual (Índice de precios al productor por producto: todos los productos)
1980 – 2006: S&P GSCI Rendimiento total de productos básicos (SPGSCITR)
2006 – 2022: DBC ETF (Invesco DB Commodity Index Tracking Fund)
En primer lugar, entre 1926 y 1979 ajustamos el índice PPI para tener en cuenta la versión beta correcta de los precios de las materias primas. En segundo lugar, utilizamos el exceso de rendimiento del sector de la energía de renta variable frente a todo el mercado como nuestro proxy de volatilidad diaria. Aplicamos la Extrapolación Proxy de Volatilidad de Quantpedia y obtuvimos datos diarios de esta fuente mensual.
Si está interesado en los detalles específicos de cualquiera de los pasos, consulte nuestro artículo Ampliación de los datos históricos diarios de materias primas a 100 años .
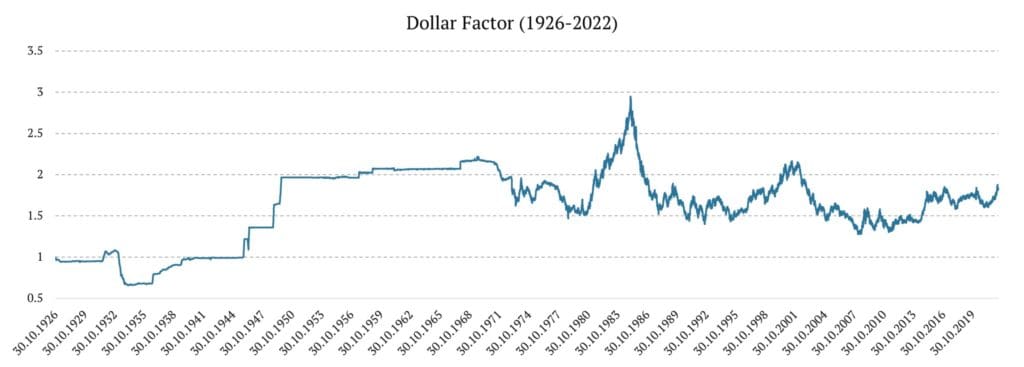
El factor dólar estadounidense
El factor del dólar estadounidense se construyó utilizando 3 fuentes de datos diferentes:
1926 – 1953: las tasas de divisas cruzadas se obtuvieron de riksbank.se.
1953 – 1971: las tasas de cambio cruzadas se obtuvieron de bis.org
1971 – 2007: obtuvimos el índice del dólar estadounidense de Wikipedia
2007 – 2022: utilizamos UUP ETF ( Invesco DB US Dollar Index Bullish Fund )
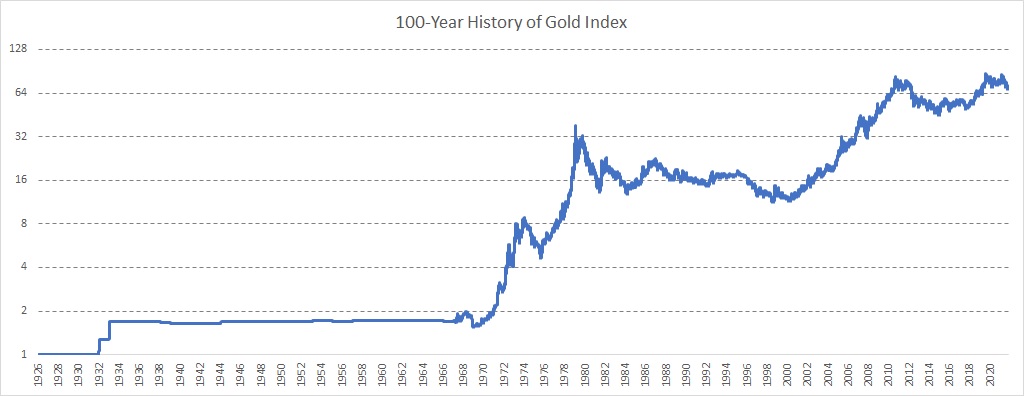
Oro
El índice de oro se construyó en tres pasos:
1926 – 1968: Utilizamos los precios mensuales del oro y la interpolación lineal para obtener el índice diario del oro.
1968 – 2004: Utilizamos los precios al contado diarios del oro
2004 – 2022: GLD ETF (Acciones SPDR Gold)
Margen de renta variable mundial sin EE. UU. (WorldExUS)
El factor WorldExUS se construyó en varios pasos y utilizó múltiples fuentes de datos.
1926 – 1972: renta variable mundial mensual ex EE. UU.
1972 – 2002: Daily World ex EE. UU. Acciones
2002 – 2007: ETF EFA (iShares MSCI EAFE ETF)
2007 – 2022: VEU ETF (Vanguard FTSE All-World ex-US Index Fund)
De manera similar a los datos de bonos anteriores, aplicamos la extrapolación del proxy de volatilidad de Quantpedia para transformar los datos mensuales de la primera fuente en datos diarios. Utilizamos las acciones estadounidenses como fuente de volatilidad diaria. En pocas palabras, copiamos la volatilidad diaria de las acciones de EE. UU., la conectamos entre dos puntos de datos mensuales y nos aseguramos de que no haya saltos ni lagunas en los datos, y que todo suceda de forma lineal.
Utilizamos datos de renta variable mundial excepto EE. UU. en forma de diferencial frente a la renta variable estadounidense. Para comprender mejor toda la metodología, recomendamos leer nuestro artículo.

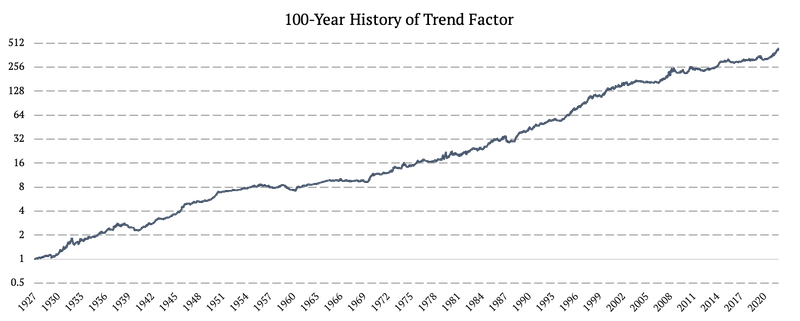
Estrategia de seguimiento de tendencias de activos múltiples (Tendencia)
A diferencia de los factores anteriores, este factor se construye como una estrategia comercial activa negociable y replicable. La estrategia opera con 3 clases de activos diferentes: bonos (factor: US10Y), acciones (factor: US EQUITIES) y materias primas (factor: materias primas) y aplica una lógica de seguimiento de tendencias. Cada mes observamos varias tendencias de bonos, acciones y materias primas y tomamos posiciones largas si la tendencia es positiva o posiciones cortas si es negativa. Luego ponderamos los activos con base en un esquema de ponderación de risk parity.
Dividimos la estrategia en nueve subestrategias para evitar el «sesgo de la suerte del momento». La estrategia también utiliza varios horizontes de seguimiento de tendencias. Todas las estrategias se reequilibran mensualmente, pero en días diferentes.
CRIPTOMONEDAS
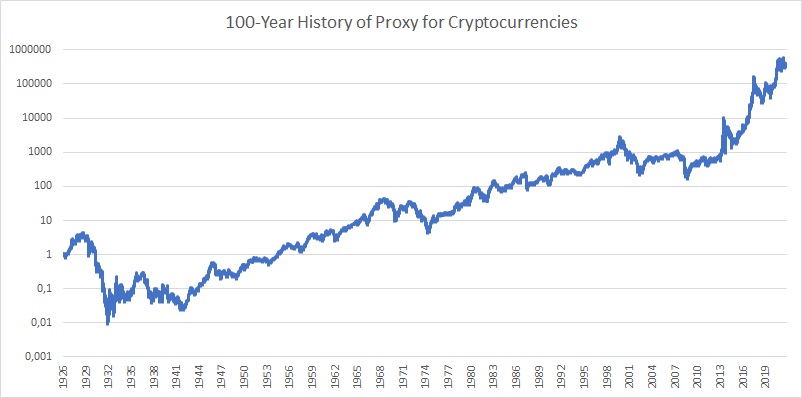
Las criptomonedas son las series temporales más difíciles de modelar porque son la clase de activos más importante más joven. Sin embargo, podemos intentar basar nuestra serie temporal de criptomonedas sintéticas de 100 años en un trabajo de investigación que las compare con acciones beta de alto sentimiento . Nuestra propia investigación confirma que las criptos están altamente correlacionadas con las acciones, especialmente durante las recesiones del mercado. Por lo tanto, decidimos extender los rendimientos de las criptomonedas al pasado mediante el uso de una combinación de asignación del 100 % al quintil Book-to-Market de Fama y French Small Cap Low más una asignación del 100 % al quintil de Book-to-Market de Fama y French Small Cap Low. La cartera de F&F resultante que tiene una asignación del 200% (principalmente a acciones de crecimiento) se ajusta al rendimiento y la volatilidad de las criptomonedas de manera relativamente satisfactoria.
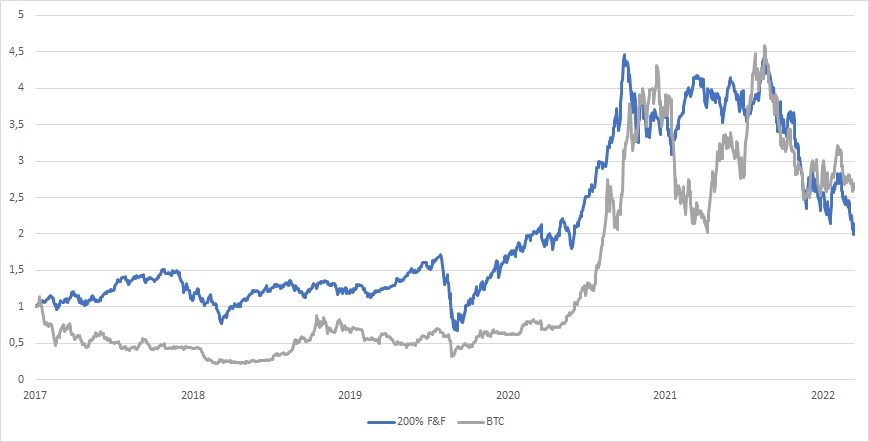
Por supuesto, reconocemos que nuestro proxy del factor de criptomoneda se puede mejorar. Planeamos profundizar más en este tema en el futuro y encontrar un modelo que se ajuste aún mejor y que se pueda usar como proxy para un historial extenso de precios de criptomonedas… Pero el proxy actual también se puede usar. Así que para resumir:
1926 – 2015: 100 % Fama y SMALL francés LoBM + 100 % Fama y BIG LoBM francés
2015 – 2022: Precio de Bitcoin
Modelo de regresión multifactorial
Después de construir un historial de 100 años para cada factor, estamos listos para pasar al modelo de regresión en sí.
El modelo utiliza el criterio de información de Akaike (AIC), que estima la «calidad» de un modelo. Además, el AIC da cuenta del número de parámetros. Por lo tanto, la cantidad de parámetros (factores relacionados con la estrategia dada) no debe ser demasiado alta para obtener un modelo significativo pero simple con interpretaciones directas.
Empleamos el AIC en una selección de modelos usando la regresión Stepwise con selección hacia adelante.
Supongamos que tenemos la curva de equidad de alguna estrategia (variable independiente). Comenzamos con un conjunto de variables predeterminadas que consta de varios «factores», específicamente, todos los factores enumerados en la sección anterior.
De manera más general, supongamos que tenemos n factores. En el primer paso, construimos numerosos modelos que usan solo uno de los factores (un factor = un modelo). Por lo tanto, nos quedan tantos modelos como factores posibles (n modelos). A continuación, calculamos el AIC para cada modelo y, en función del AIC, seleccionamos el mejor modelo. Como siguiente paso, tratamos de agregar otro factor del conjunto reducido de factores que podrían mejorar nuestro modelo. El algoritmo genera n menos uno modelos, calcula el AIC de cada modelo y elige el mejor modelo.
El proceso donde se agrega un nuevo factor, basado en el AIC, continúa hasta que el AIC ya no mejora. Si el AIC no mejora, significa que la complejidad del modelo no superaría la bondad del ajuste del modelo.

Replicar un ETF balanceado
Ahora que explicamos cómo funciona el modelo, presentamos un ejemplo. Reproducimos AOR (ETF de asignación de crecimiento central de iShares) usando nuestros factores. De iShares : «El ETF de asignación de crecimiento principal de iShares busca rastrear los resultados de inversión de un índice compuesto por una cartera de fondos subyacentes de renta variable y renta fija destinados a representar una estrategia de riesgo objetivo de asignación de crecimiento».
El AOR ETF tiene un historial desde noviembre de 2008, por lo que el ajuste se realiza durante este período. La siguiente figura presenta las curvas de acciones de AOR (nuestra cartera de entrada) y la cartera de factores (cartera imitadora) con los factores elegidos, sus pesos, errores estándar y valores t-stat.
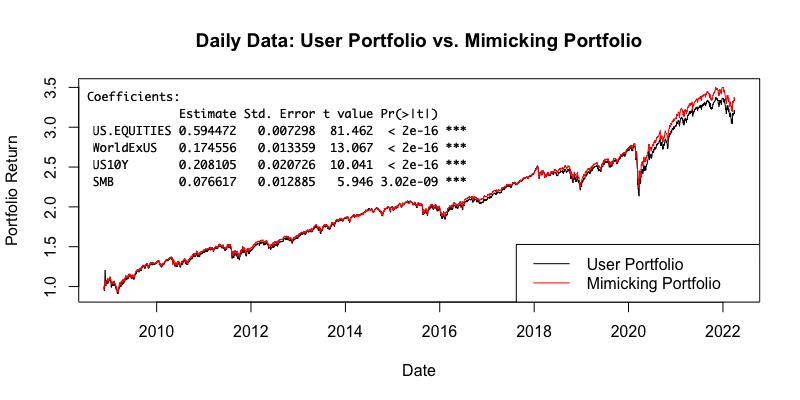
Como podemos ver, el modelo eligió cuatro factores estadísticamente significativos : US EQUITIES (41,992%), WorldExUS (17,456%), US10Y (20,810%), SMB (7,662%). Y estos factores imitan muy bien la cartera de entrada (AOR US), casi llegando a una cartera idéntica. Por lo tanto, gracias a nuestro modelo, podemos decir con bastante precisión qué factores impulsan los rendimientos de la cartera subyacente .
A continuación también presentamos las características de riesgo/rendimiento de ambas carteras.

100 años de datos diarios de ETF
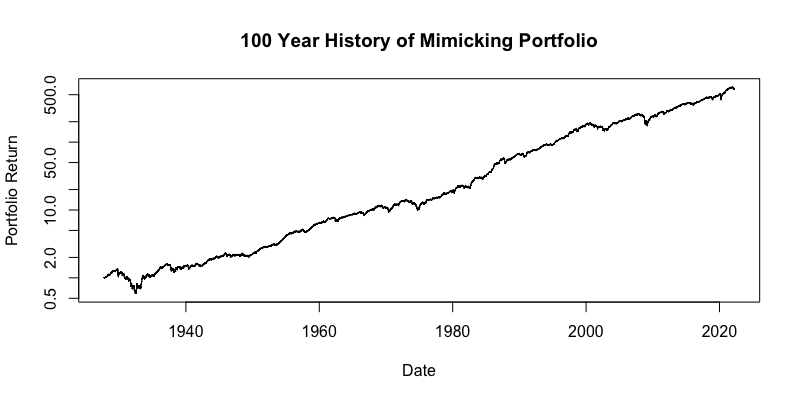
Finalmente, usamos los pesos factoriales calculados de nuestro modelo de regresión y los aplicamos a los mismos factores con un historial de 100 años. La siguiente figura muestra la curva de renta variable de la cartera imitadora durante el siglo pasado. El gráfico utiliza el eje y log10.
Adicionalmente, presentamos las características de riesgo y retorno de la cartera imitadora.

Como podemos ver arriba, pudimos replicar los datos de ETF de AOR US hace 100 años en la historia, hasta 1927. Esto nos brinda una gran perspectiva sobre el desarrollo potencial del ETF en todo tipo de escenarios de mercado alcistas o bajistas. Ahora tenemos una mejor comprensión de los posibles eventos de riesgo y también podemos hacer suposiciones mucho más realistas para el rendimiento en varios escenarios y condiciones de mercado.
Conclusión
Esperamos que este artículo responda múltiples preguntas, incluido por qué es útil poder imitar cualquier cartera con factores con un historial de 100 años. Explicamos cómo creamos una historia tan larga para cada uno de nuestros 16 factores y por qué los elegimos para empezar.
Posteriormente, presentamos el modelo de regresión multifactorial, que selecciona los factores de imitación óptimos de los que se compone la cartera de imitación. El modelo utiliza el criterio de información de Akaike (AIC) para penalizar factores innecesarios, por lo que nos queda un modelo que es lo más simple posible con una interpretación directa.
Luego presentamos AOR US ETF como una cartera de casos de uso y la comparamos con la cartera de factores compuesta por cuatro factores replicantes, determinados por el modelo de Quantpedia. En primer lugar, comparamos el ETF original y la cartera que imita el factor durante la breve historia (historia de AOR), y llegamos a la conclusión de que la replicación del factor para este ETF es casi perfecta.
Por último, y lo más importante, ampliamos nuestro análisis a una historia de 100 años y analizamos el desempeño de la cartera de factores durante el último siglo. De esta manera, pudimos estimar con bastante precisión el riesgo y el rendimiento del ETF durante los últimos 100 años.
Finalmente, esperamos que hayas disfrutado este artículo, porque pronto habrá más. Ya estamos trabajando en el artículo de seguimiento, que profundizará en los 100 años de historia de la cartera de factores.
Autora:
Daniela Hanicova, analista cuántica, Quantpedia