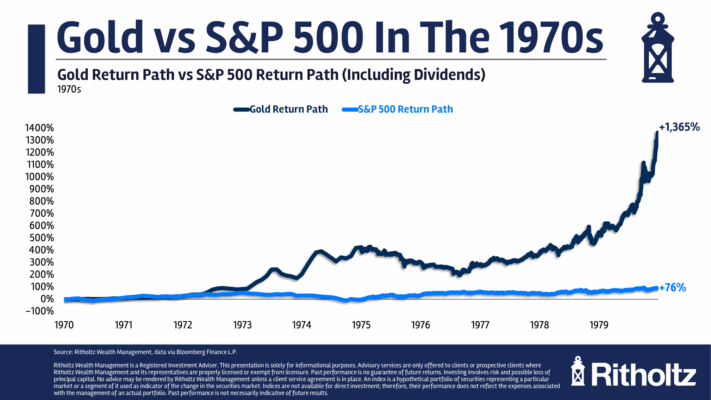
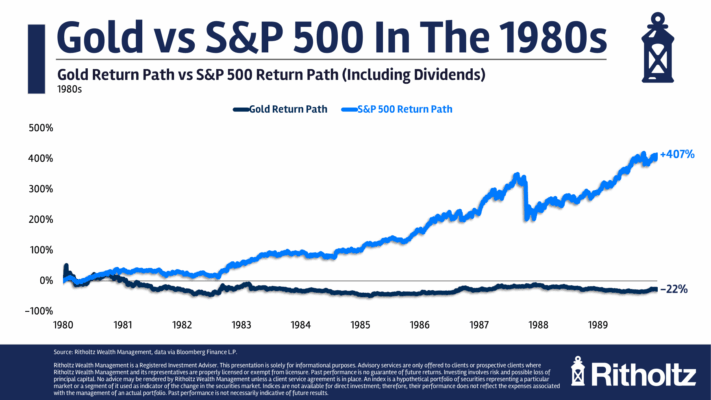
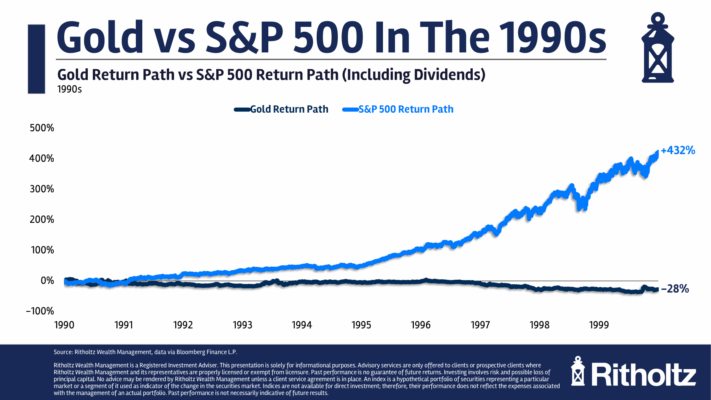
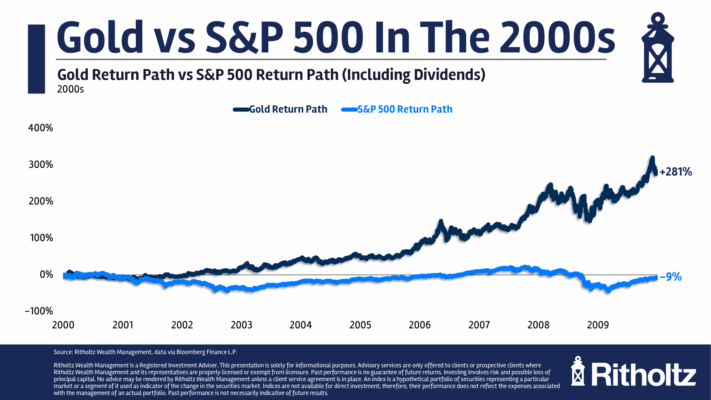
Selección de características en la era de la IA generativa por Ernest P. Chan

El doctor Ernest P. Chan, es fundador de PredictNow.ai Inc. La carrera de Ernie desde 1994 se ha centrado en el desarrollo de modelos estadísticos y algoritmos informáticos avanzados. Ha aplicado su experiencia en aprendizaje automático en IBM T.J. El grupo de tecnologías del lenguaje humano del Centro de Investigación Watson, en el Grupo de Minería de Datos e Inteligencia Artificial de Morgan Stanley y en el Grupo de Trading Horizon de Credit Suisse. También es el fundador y miembro gerente de una empresa de gestión de inversiones cuantitativas, QTS Capital Management, LLC. Ernie ha sido mencionado por el Wall Street Journal, el New York Times, Forbes y la revista CIO, y entrevistado en el programa Closing Bell de CNBC, y la revista Technical Analysis of Stocks and Commodities.
QTS Capital Management, LLC.
Las características son los insumos de los algoritmos de aprendizaje automático. A veces también se llaman variables independientes, covariables o simplemente X. Pueden usarse para aprendizaje supervisado o no supervisado, o para optimización. Por ejemplo, en QTS utilizamos más de 100 de ellas como entradas para calibrar dinámicamente la asignación entre nuestra estrategia Tail Reaper y los futuros del E-mini S&P 500. En general, los modeladores no saben de antemano qué características son útiles o redundantes para una aplicación específica. Usar todas las características puede generar sobreajuste y un rendimiento deficiente fuera de muestra, o incluso inestabilidad numérica y singularidades al invertir matrices. De ahí la necesidad de un proceso llamado selección de características.
En la IA convencional o discriminativa, intentamos modelar la probabilidad P(Y|X), donde Y es la variable dependiente, el objetivo o la etiqueta. Los traders cuantitativos suelen usar modelos basados en árboles, como los gradient-boosted trees (GBT), y algoritmos de selección de características como MDA, SHAP o LIME para elegir un subconjunto útil para modelar P(Y|X). En la IA generativa (GenAI), las características adoptan un papel mucho más central que la variable objetivo. Se construyen redes neuronales profundas (DNN) solo para modelar la distribución de probabilidad de X, sin importar qué Y se quiera predecir después.
A menudo, se preentrena una DNN con un objetivo (por ejemplo, modelar bien la distribución de X) y luego se usa para otro (como optimizar una recompensa mediante aprendizaje por refuerzo profundo). Ya no podemos usar MDA, SHAP o LIME cuando Y aún no está definida. Pero, más importante aún, estos métodos tradicionales son globales: no permiten selección de características específica por muestra. Una vez seleccionado un conjunto de características, se usa para todas las inferencias, lo que limita la adaptabilidad del modelo.
A continuación se discuten dos metodologías potentes y ampliamente conocidas en el aprendizaje profundo y la IA generativa que pueden emplearse para la selección de características: el transformer y el autoencoder variacional (VAE). Pueden usarse para preentrenar una DNN para distintas aplicaciones posteriores o con grandes conjuntos de datos no etiquetados, permiten selección de características por muestra y pueden entrenarse conjuntamente con los parámetros de la DNN mediante una sola función objetivo.
El transformer
En los transformers con autoatención (self-attention), la suma de las puntuaciones de atención en una columna de la matriz de atención indica la importancia de la característica correspondiente. Si multiplicamos la matriz de atención por las características de entrada (o alguna transformación lineal de ellas), obtenemos el vector de contexto Z, es decir, una versión transformada de las características ponderadas por su importancia. Estas ponderaciones dependen de los valores de las propias características, por lo que son específicas de cada muestra.
El transformer se entrena para lograr un objetivo, como maximizar la verosimilitud logarítmica de una tarea de clasificación. También puede preentrenarse de manera no supervisada, reconstruyendo las características originales (en lugar de predecirlas) y usando el Error Cuadrático Medio (MSE) como función de pérdida. Una vez entrenado, el transformer puede usarse sin modificación en tareas posteriores (regresión u optimización) o ajustarse finamente (fine-tuning) para optimizar otros objetivos.
Este paradigma de preentrenamiento y ajuste fino es una de las razones por las que la IA generativa es tan poderosa frente a la discriminativa: permite entrenar un modelo con grandes volúmenes de datos no etiquetados y luego adaptarlo con pocos datos específicos. Por ejemplo, para predecir los rendimientos de AAPL, podríamos preentrenar el transformer con datos de MSFT o GOOG y después afinarlo con los de AAPL, mitigando el problema crónico de escasez de datos en el aprendizaje automático financiero.
Además, los transformers de atención cruzada (cross-attention) permiten mezclar características temporales (VIX, tipos de interés, factor HML, etc.) con transversales (ratios P/E, B/M, rentabilidad por dividendo, etc.), o entre distintos instrumentos (NVDA, GOOG, etc.). Si se usan las características transversales como “consulta” (query) y las temporales como “clave/valor” (key/value), la suma de las puntuaciones de atención muestra la importancia de cada característica temporal al predecir, por ejemplo, el retorno de una acción. Esto permite incorporar contexto macroeconómico a los fundamentales de cada valor.
Ejemplo: predicción de rendimientos del SPX
Supongamos que intentamos predecir los retornos del S&P 500 (SPX). Si se invierte mediante una estrategia de buy-and-hold, el Sharpe ratio fue de 0,39 entre 2005–2017 y de 0,8 entre 2017–2025. Usamos el primer periodo como conjunto de entrenamiento y el segundo como prueba. Con 14 características técnicas creadas con la librería TA-LIB, se entrena una red neuronal MLP con una capa oculta de 2 nodos para predecir el retorno del día siguiente e ir largo si la predicción es positiva. El Sharpe obtenido fue (0,4, 1,1), superando la estrategia de comprar y mantener.
Luego, al usar un transformer de autoatención con 64 dimensiones de “embeddings”, características con rezagos de 1 a 4 días y el mismo MLP, el Sharpe fue (0,7, 0,6). Aunque sigue siendo mejor que el buy-and-hold, no supera al MLP con las características originales, mostrando que los transformers requieren muchos datos y una cuidadosa optimización de hiperparámetros. Añadir solo el VIX como entrada temporal (key/value) dio un Sharpe de (0,3, 0,6), sin mejora. En la práctica, QTS y Predictnow.ai emplean cientos de características macro y de mercado como entradas, obteniendo resultados más consistentes.
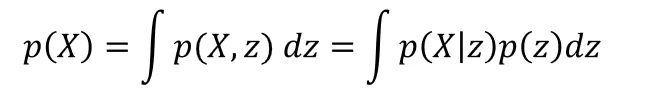
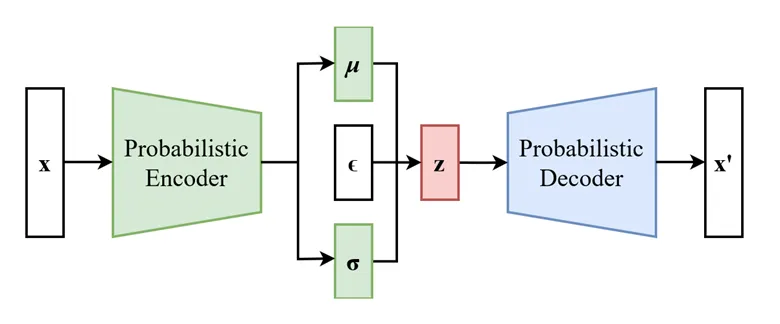
Autoencoder variacional (VAE)
El VAE es otro método de selección de características y puede verse como una versión más general del PCA, el modelo de mezcla gaussiana (GMM) o el modelo oculto de Markov (HMM). Todos ellos convierten las características observables X en un conjunto más pequeño de variables latentes z que generan X con distribuciones más simples (como una gaussiana).
En el VAE, el encoder aprende p(z|X) y el decoder aprende p(X|z). Ambos se modelan con redes neuronales profundas separadas, entrenadas conjuntamente para minimizar la verosimilitud negativa de X. Una vez entrenado, el VAE convierte las características observables en un vector latente z que puede usarse como entrada para tareas supervisadas o de optimización, de forma similar al vector de contexto Z del transformer.
También es posible entrenarlo de forma semisupervisada (Kingma y Welling, 2019), combinando datos etiquetados y no etiquetados. En clasificación de imágenes, con solo 10 etiquetas por clase se logró más del 99% de precisión, lo que demuestra su enorme potencial para aplicaciones financieras con pocos datos etiquetados.
Ejemplo SPX con VAE
Usando el mismo vector de 14 características, un VAE con vector latente de 8 dimensiones y dos capas ReLU para el encoder y el decoder obtuvo un Sharpe de (0,2, 0,4), inferior al buy-and-hold. Esto indica que se requiere una optimización más profunda de la arquitectura y, sobre todo, preentrenamiento con datos adicionales.
Conclusión
Los transformers y los autoencoders variacionales muestran que la transformación y selección de características son ahora un componente central en la IA generativa, y no un paso posterior como en los modelos discriminativos tradicionales. También evidencian la flexibilidad de los enfoques generativos, especialmente la capacidad de preentrenar modelos con grandes volúmenes de datos no etiquetados y ajustarlos gradualmente a medida que llega nueva información. Su potencial en las aplicaciones financieras apenas comienza a ser explotado por los grupos de trading cuantitativo más sofisticados.
 ">
">


 ">
">

 ">
">



 ">
">


 ">
">


 ">
">


 ">
">

 ">
">

 ">
">


 ">
">
 ">
">


 ">
">


 ">
">



 ">
">

 ">
">